
对数据集进行排序和排名的是常用最基础的数据分析手段,pandas提供了方便的排序和排名的方法,通过简单的语句和参数就可以实现常用的排序和排名。
本文以student数据集的DataFrame为例来演示和介绍pandas数据分析之排序和排名(sort和rank)。 数据集内容如下,包括学生的学号、姓名、年龄及语文、数学、英语的成绩:
import pandas as pd
import numpy as np
df = pd.read_excel('D:\\Python\\study\\pythontest\\pandastest\\数据集\\student.xlsx')
df
 数据集及源代码见:https://github.com/xiejava1018/pandastest.git
数据集及源代码见:https://github.com/xiejava1018/pandastest.git
一、排序
对数据集进行排序是是常用的数据分析需求之一。pandas提供了按 索引标签排序sort_index()和按值排序sort_values()两种排序方法。对于DataFrame,可以根据任意一个轴上的索引标签进行排序。默认顺序排序,也可以设置按倒序排序。
1、按标签排序
1)按行标签索引排序
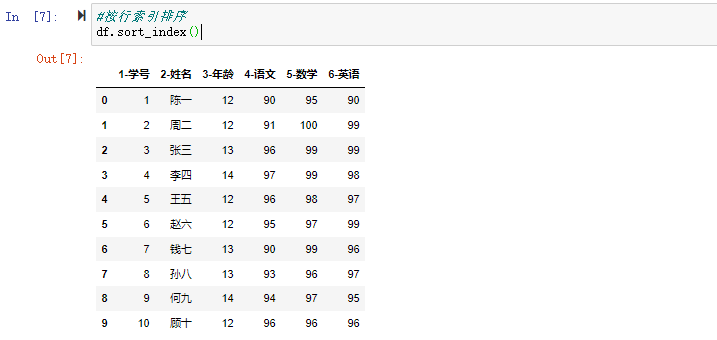
pandas默认按行标签索引顺序排序
#按行索引排序
df.sort_index()
 可以通过设置
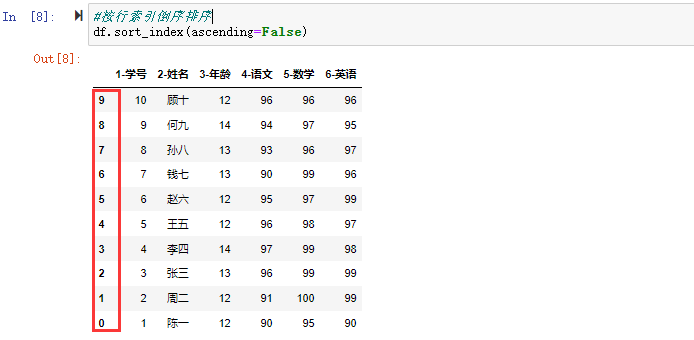
可以通过设置ascending=False参数进行倒序排序
#按行索引倒序排序
df.sort_index(ascending=False)
2)按列标签索引排序
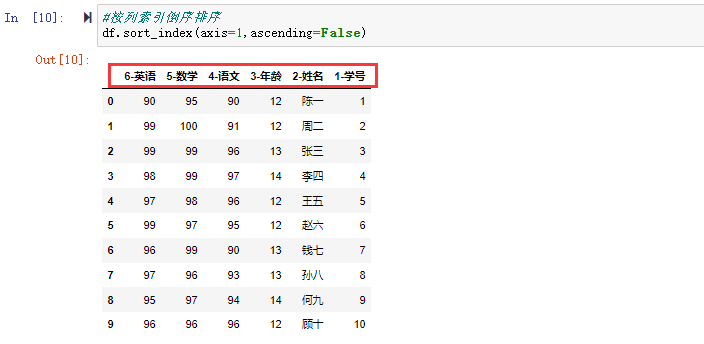
通过给 axis 轴参数传递 0 或 1,可以对列标签进行排序。默认情况下,axis=0 表示按行排序;而 axis=1 则表示按列排序。
#按列索引排序
df.sort_index(axis=1)
 同样可以设置ascending=False参数进行倒序排序
同样可以设置ascending=False参数进行倒序排序
#按列索引倒序排序
df.sort_index(axis=1,ascending=False)
2、按值排序
在实际应用中用得最多的应该是根据某一列的值进行排序。在pandas中可以通过sort_value(),在sort_value中可以设定按某个列排序,也可以通过sort_value(by=[]),通过设置by=[‘a’,'b']列表来指定多个需要排序的列。
1)对单个列的值排序
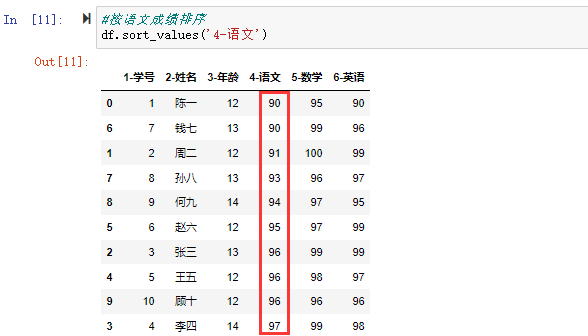
如在数据集中对语文成绩进行排序。
#按语文成绩排序
df.sort_values('4-语文')
2)对多个列的值进行排序
通过设置by=[‘a’,'b']列表来指定多个需要排序的列。 如对数据集中的语文和数学进行排序
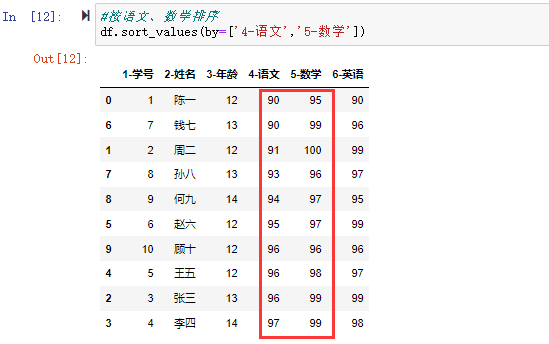
#按语文、数学排序
df.sort_values(by=['4-语文','5-数学'])
3、排序算法
sort_values() 提供了参数kind用来指定排序算法。这里有三种排序算法:
- mergesort(归并排序)
- heapsort(堆排序)
- quicksort(快速排序)
默认为 quicksort(快速排序) ,其中 mergesort归并排序是最稳定的算法。 具体用法如下:
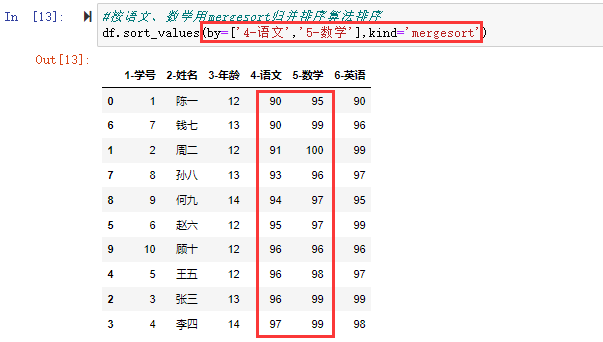
#按语文、数学用mergesort归并排序算法排序
df.sort_values(by=['4-语文','5-数学'],kind='mergesort')
二、排名
排名和排序的区别在于排序一定是有顺序,而排名分先后并列。如在现实生活中相同的分数存在排名并列的情况。 在《使用python进行数据分析》一书中对rank排名的描述为:排名是指对数组从1到有效数据点总数分配名次的操作。Series和DataFrame的rank方法是实现排名的方法,默认情况下,rank是通过“为各组分配一个平均排名”的方式破坏平级关系。这段话讲得是什么鬼?其实就是在存在并列排名的时候采用一定的策略来打破这种关系。 排名中的平级关系打破方法有如下几种:
| method | 说明 |
|---|---|
| average | 默认:在每个组中分配平均排名 |
| min | 对整个组使用最小排名 |
| max | 对整个组使用最大排名 |
| first | 按照值在数据中出现的次序分配排名 |
| dense | 类似于method='min',但组件排名总是加1,而不是一个组中的相等元素的数量 |
rank()函数原型:rank(axis=0, method: str = 'average', numeric_only: Union[bool, NoneType] = None, na_option: str = 'keep', ascending: bool = True, pct: bool = False)
这里method取值可以为'average','first','min', 'max','dense',用来打破排名中的平级关系的。
光看这些说明还是比较难理解。下面通过实例来说明:
1、默认average 排名
在数据集中我们只取“学号”、“姓名”、“语文”,然后取“语文”的排名,默认average
df_rank=df[['1-学号','2-姓名','4-语文']].copy()
#按语文成绩进行rank的默认排名
df_rank['语文排名']=df_rank['4-语文'].rank(ascending=False)
df_rank.sort_values(by='语文排名')
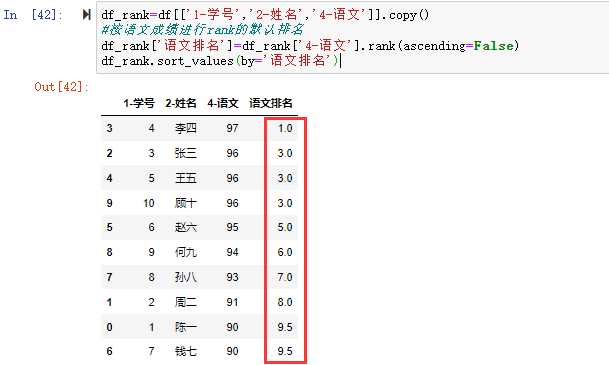
这个排名很奇怪,97分排名第一没有问题,居然没有第二名,三个96分排名均为3,还有两个90分排名为9.5。这是什么鬼? 原来这就是默认的“average”规则,成绩相同时,取顺序排名中所有名次之和除以该成绩的个数,如两个90分的名次为最后两名分别为9名和10名,即(9+10)/2=9.5,三个96分的名次分别为2、3、4 那么排名为(2+3+4)/3=9/3=3
2、mothod='min'的排名
#按语文成绩进行min排名
df_rank['语文排名']=df_rank['4-语文'].rank(method='min',ascending=False)
df_rank.sort_values(by='语文排名')
![]()
在这个排名中看到有3个并列为2的排名,但没有排名为3、4的,有两个排名为9的,但没有排名为10的。可以看出当method=“min”时,成绩相同的同学,取在顺序排名中最小的那个排名作为该值的排名,张三、王五、顾十三个同学都是96分排名分别为2、3、4,那么当method为min时,取2、3、4的最小的那个作为成绩为96的整体排名即第2名。因为有了三个2名,接下来就从5名开始,5、6、7、8,到了第9名又有两个同分数的取9、10的最小排名为9,所以有两个9名。
3、mothod='max'的排名
#按语文成绩进行max排名
df_rank['语文排名']=df_rank['4-语文'].rank(method='max',ascending=False)
df_rank.sort_values(by='语文排名')
![]() 与min相反,成绩相同的同学,排名相同取顺序最大的排名,张三、王五、顾十三个同学都是96分排名分别为2、3、4,那么当method为min时,取2、3、4的最小的那个作为成绩为96的整体排名即第2名。当method为max时,取最大的4作为96分的整体排名,同理90分的取10为90分的整体排名。
与min相反,成绩相同的同学,排名相同取顺序最大的排名,张三、王五、顾十三个同学都是96分排名分别为2、3、4,那么当method为min时,取2、3、4的最小的那个作为成绩为96的整体排名即第2名。当method为max时,取最大的4作为96分的整体排名,同理90分的取10为90分的整体排名。
4、mothod='first'的排名
#按语文成绩进行first排名
df_rank['语文排名']=df_rank['4-语文'].rank(method='first',ascending=False)
df_rank.sort_values(by='语文排名')
![]()
first排名很好理解了,有点先到先得的意思,成绩相同,谁的索引排前,谁的排名就靠前,比如张三、王五、顾十 这三个同学都是96分,按理应该是并列第2,但张三的索引比王五和顾十的都靠前,王五的索引比顾十靠前,所以他们的顺序分别为2、3、4,同理陈一、钱七的分数都是90分,但陈一的索引比钱七靠前所以陈一排名为9、钱七排名第10
5、mothod='dense'的排名
#按语文成绩进行dense排名
df_rank['语文排名']=df_rank['4-语文'].rank(method='dense',ascending=False)
df_rank.sort_values(by='语文排名')
![]() "dense": 是密集的意思,也比较好理解,即相同成绩的同学排名相同,其他依次加1即可。可以看到张三、王五、顾十这三位同学都是96分,并列排名第2,后面的加1,即比他们分数稍低的赵六95分排名第3,后面依次。
"dense": 是密集的意思,也比较好理解,即相同成绩的同学排名相同,其他依次加1即可。可以看到张三、王五、顾十这三位同学都是96分,并列排名第2,后面的加1,即比他们分数稍低的赵六95分排名第3,后面依次。
6、不同method的排名对比
最后不同method的排名对比:
#按语文成绩进行rank的默认排名
df_rank['语文排名-average']=df_rank['4-语文'].rank(ascending=False)
#按语文成绩进行min排名
df_rank['语文排名-min']=df_rank['4-语文'].rank(method='min',ascending=False)
#按语文成绩进行max排名
df_rank['语文排名-max']=df_rank['4-语文'].rank(method='max',ascending=False)
#按语文成绩进行first排名
df_rank['语文排名-first']=df_rank['4-语文'].rank(method='first',ascending=False)
#按语文成绩进行dense排名
df_rank['语文排名-dense']=df_rank['4-语文'].rank(method='dense',ascending=False)
df_rank.sort_values(by='4-语文',ascending=False)

数据集及源代码见:https://github.com/xiejava1018/pandastest.git
作者博客:http://xiejava.ishareread.com/

关注:微信公众号,一起学习成长!