
Python实现爬虫是很容易的,一般来说就是获取目标网站的页面,对目标页面的分析、解析、识别,提取有用的信息,然后该入库的入库,该下载的下载。以前写过一篇文章《Python爬虫获取电子书资源实战》,以一个电子书的网站为例来实现python爬虫获取电子书资源。爬取整站的电子书资源,按目录保存到本地,并形成索引文件方便查找。这次介绍通过Scrapy爬虫框架来实现同样的功能。
一、Scrapy简介
Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架。 Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。 通常我们可以很简单的通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。
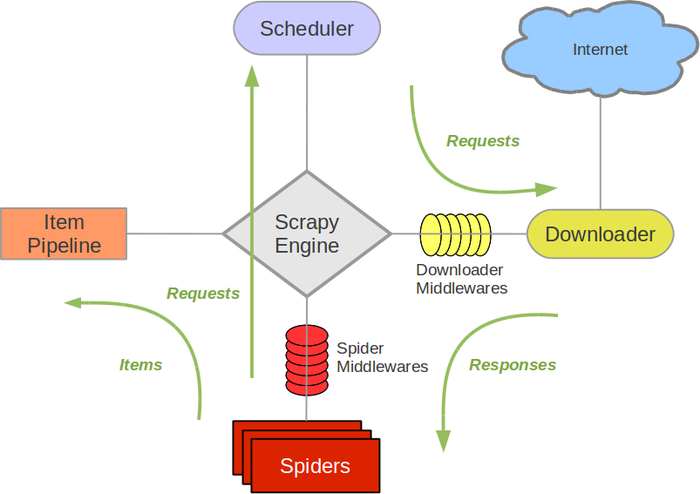
- Scrapy Engine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
- Scheduler(调度器):它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
- Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器).
- Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
- Downloader Middlewares(下载中间件):可以当作是一个可以自定义扩展下载功能的组件。
- Spider Middlewares(Spider中间件):可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
二、Scrapy实战
虽然用python写一个爬虫也不是很费事,但是有了Scrapy以后让你实现爬虫更简单,更加通用,现在我们还是以《Python爬虫获取电子书资源实战》中的例子,爬取目标网站kgbook.com。也可以对比看一下通过Scrapy爬虫框架实现相同的功能有多么的方便。
1、Scrapy安装
首先通过 pip 安装 Scrapy 框架
pip install Scrapy
2、创建Scrapy项目工程
创建getbooks的项目
scrapy startproject getbooks
创建一个getkgbook的爬虫,目标网站kgbook.com
scrapy genspider getkgbook kgbook.com
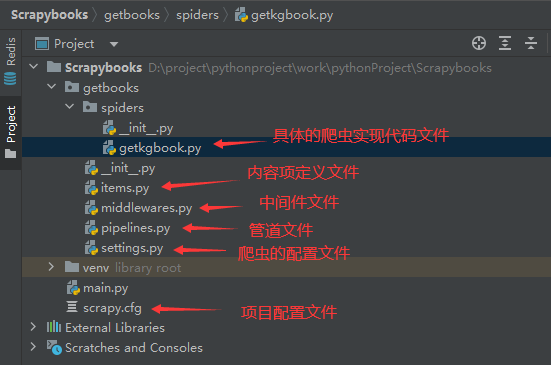
项目的结构如下图所示
3、实现Scrapy的爬虫代码
爬数据
主要的爬虫逻辑实现代码都在getkgbook.py中,在这里实现目录的爬取、翻页、进入到详情页,并解析详情页的数据。 getkgbook.py
import os
import re
import scrapy
from getbooks.items import KgbookItem
class GetkgbookSpider(scrapy.Spider):
name = "getkgbook" #爬虫的名称
allowed_domains = ["kgbook.com"] #爬取的网站
start_urls = ["https://kgbook.com"] #爬取的首页
def parse(self, response):
categorys = response.xpath('//div[@id="category"]/div/ul/li/a')
for category in categorys:
category_url = category.xpath('./@href').extract_first()
url=response.urljoin(category_url)
#爬取进入到目录页
yield response.follow(url, self.parse_booklist)
#解析目录页
def parse_booklist(self,response):
book_list_select=response.css('.channel-item h3.list-title a')
#获取书籍列表
for book_info_select in book_list_select:
book_name=book_info_select.css('::text').extract_first()
book_detail_url=book_info_select.css('::attr(href)').extract_first()
book_detail_url=response.urljoin(book_detail_url)
print(book_name,book_detail_url)
yield scrapy.Request(url=book_detail_url, callback=self.pase_bookdetail)
#翻页
nextpage_url = response.xpath('//div[@class="pagenavi"]/a[contains(text(), "下一页")]/@href').extract_first()
if nextpage_url:
yield response.follow(nextpage_url, self.parse_booklist)
#解析详情页
def pase_bookdetail(self,response):
navegate=response.xpath('//nav[@id="location"]/a')
if len(navegate)>1:
book_category=navegate[1].xpath('./text()').extract_first()
book_name=response.css('.news_title::text').extract_first()
book_author=response.xpath('//div[@id="news_details"]/ul/li[contains(text(),"作者")]/text()').extract_first()
pattern=re.compile('mobi|epub|azw3|pdf',re.I) #解析书籍的类型
book_download_urls=response.xpath('//div[@id="introduction"]/a[@class="button"]')
for book_download_urlinfo in book_download_urls:
book_type=book_download_urlinfo.re(pattern)
if book_type:
book_download_url=book_download_urlinfo.xpath('./@href').extract_first()
#获取要下载的书籍的名称、作者、要保存的路径、下载地址
item=KgbookItem()
item['book_name']=book_name
item['book_author']=book_author
item['book_file']=os.path.join(book_category,book_name+"."+str(book_type[0]).lower())
item['book_url']=book_download_url
print(book_name,book_author,book_download_url,item['book_file'])
return item
在这里我们通过xpath解析器和css解析器来解析获取网页中的有用的信息。如提取a 标签的href的信息 ,提取书籍的名称、作者、下载链接等信息。
保存数据
item.py 在item.py中定义了KgbookItem类,Item 定义结构化数据字段,用来保存爬取到的数据,有点像 Python 中的 dict,但是提供了一些额外的保护减少错误。在这里定义了book_name、book_author、book_file、book_url这些信息都会通过爬虫提取后保存用来输出到文件或数据库等。
import scrapy
class KgbookItem(scrapy.Item):
book_name=scrapy.Field()
book_author=scrapy.Field()
book_file=scrapy.Field()
book_url=scrapy.Field()
下载数据
通过pipelines定义文件下载的管道类 pipelines.py
from scrapy import item, Request
from scrapy.pipelines.files import FilesPipeline
class KgBookFilePipeline(FilesPipeline):
def get_media_requests(self,item,info):
yield Request(item['book_url'],meta={'book_file':item['book_file']})
def file_path(self, request, response=None, info=None):
file_name=request.meta.get('book_file')
return file_name
这里实际上只做两件事,一是get_media_requests下载文件,二是组织文件要保存的路径。会通过相应的下载中间件将文件下载并保存在需要保存的目录。这里我们规划的保存目录是书籍目录\书名.类型。 还需要在settings.py中定义下载后保存的路径
# 保存书籍的路径
FILES_STORE='./books'
# 定义自定义下载的管道
ITEM_PIPELINES = {
"getbooks.pipelines.KgBookFilePipeline": 300,
}
加入以下定义,强制爬取、下载,并忽略301,302重定向
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
MEDIA_ALLOW_REDIRECTS = True
HTTPERROR_ALLOWED_CODES = [301,302]
至此,就通过Scrapy爬虫框架实现了一个爬虫。
运行效果
执行 scrapy crawl getkgbook -o books.json
可以看到控制台打印出来的日志,爬虫开始默默的勤勤恳恳的爬取了。
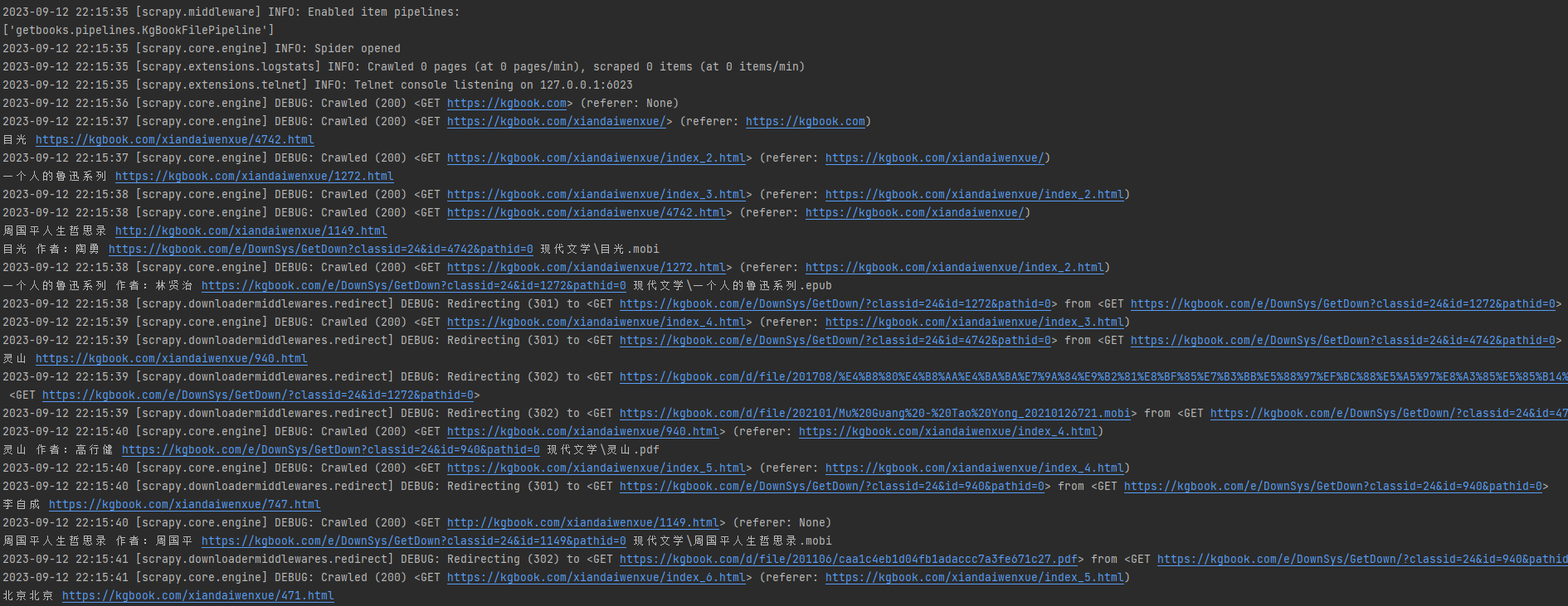
爬取的结果保存到了books.json中

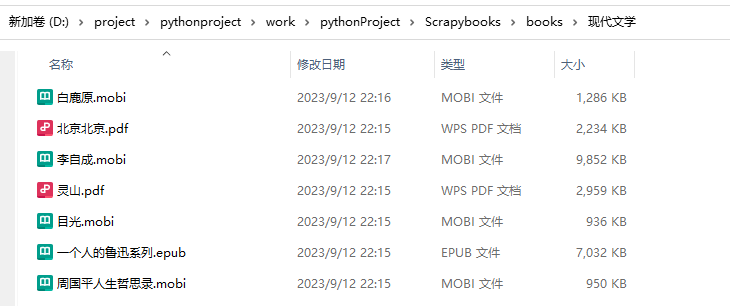
要下载的书籍也保存到了books下相应的目录下了
三、注意事项
有可能在文件下载的时候并没有把文件下载下来,原因是文件下载路径有重定向。
2023-09-12 22:25:38 [scrapy.core.engine] DEBUG: Crawled (301) <GET https://kgbook.com/e/DownSys/GetDown?classid=24&id=471&pathid=0> (referer: None)
2023-09-12 22:25:38 [scrapy.pipelines.files] WARNING: File (code: 301): Error downloading file from <GET https://kgbook.com/e/DownSys/GetDown?classid=24&id=471&pathid=0> referred in <None>
2023-09-12 22:25:38 [scrapy.core.engine] DEBUG: Crawled (301) <GET https://kgbook.com/e/DownSys/GetDown?classid=24&id=4742&pathid=0> (referer: None)
2023-09-12 22:25:38 [scrapy.pipelines.files] WARNING: File (code: 301): Error downloading file from <GET https://kgbook.com/e/DownSys/GetDown?classid=24&id=4742&pathid=0> referred in <None>
需要在settings.py中加入
MEDIA_ALLOW_REDIRECTS = True #直接下载
HTTPERROR_ALLOWED_CODES = [301,302] #忽略重定向的报错信息
现在我们通过一个Scrapy爬虫框架实例实现了网站的爬取,重代码量上看比python直接写少了很多,通用性也更强了。通过管道不仅仅可以将数据保持至json还可以保存到Excel、数据库等。
全部源代码见 https://github.com/xiejava1018/Scrapybooks
博客地址:http://xiejava.ishareread.com/

关注微信公众号,一起学习、成长!