
实现了hexo的md文件格式解析,通过什么方式怎么来迁移hexo的博客到django的博客呢?开始想到的是通过Django的manage.py的shell命令,通过shell可以执行写好的python脚本进行hexo的md文件格式解析并入库。后来想想为啥不直接自定义一个manage.py的命令直接进行迁移呢?就如我们新建Django工程迁移数据库一样,执行python manage.py migrate来迁移数据库。我们可以定义python manage.py xxx来执行的迁移hexo博客。
自定义Django-admin命令分三步:创建management文件夹、编写命令代码、测试验证
一、创建management文件夹
自定义的Django-admin管理命令本质上是一个python脚本文件,它的存放路径必须遵循一定的规范,一般位于app/management/commands目录。整个文件夹的布局如下所示:
注意app要在setting中注册
在blog/management/commands包下面创建transblog.py文件
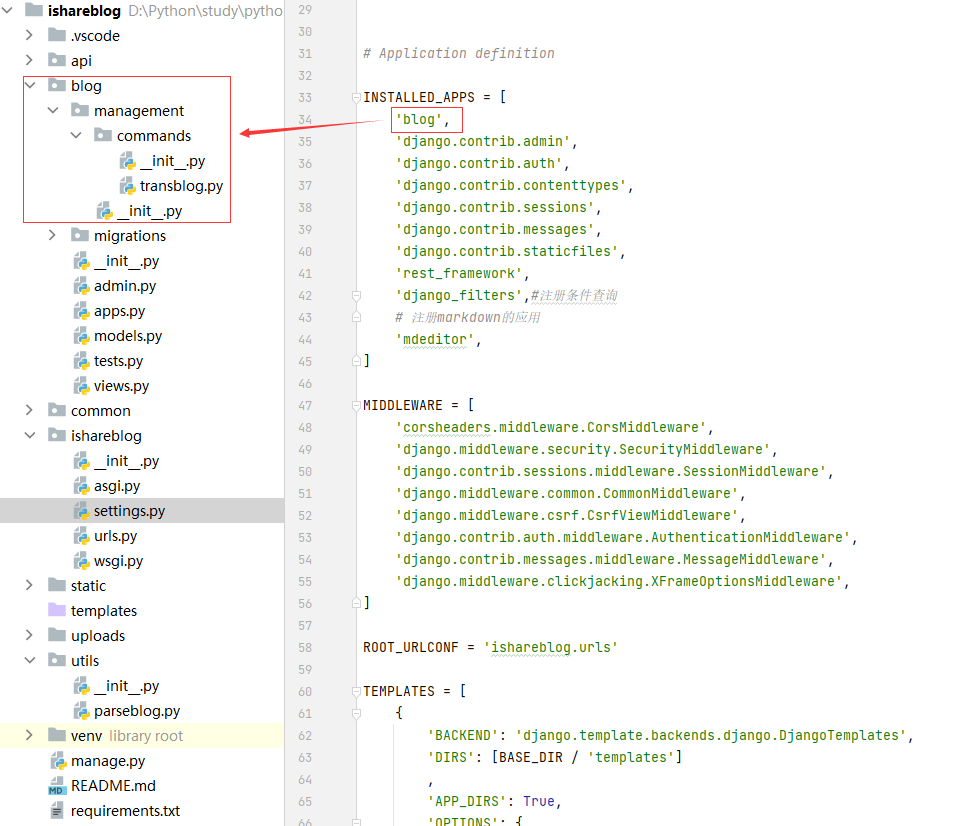
这里有两个要注意的地方:
1、app要在setting中注册。如blog在setting中注册了所以可以在blog/management/commands包下面创建transblog.py文件,api和common都没有在setting中注册所以在这两个目录下创建的不会作为管理命令生效。 2、创建的management/commands是Python包,不是单纯的目录,区别就是目录里必须有__init__.py文件,空文件都可以。
二、编写命令代码
创建命令管理文件后就可以在该文件中编写命令代码了。 每一个自定义的管理命令本质是一个Command类, 它继承了Django的Basecommand或其子类, 主要通过重写handle()方法实现自己的业务逻辑代码,而add_arguments()则用于帮助处理命令行的参数,如果运行命令时不需要额外参数,可以不写这个方法。 transblog.py的参考代码如下:
# -*- coding: utf-8 -*-
"""
:author: XieJava
:url: http://ishareread.com
:copyright: © 2021 XieJava <xiejava@ishareread.com>
:license: MIT, see LICENSE for more details.
"""
import os
from blog.models import BlogPost,BlogCategory,Tag
from utils.parseblog import parseblog
from django.core.management.base import BaseCommand
class Command(BaseCommand):
help='读取指定目录的.md文件解析至ishareblog'
def add_arguments(self, parser):
parser.add_argument('--path',help='输入.md文件的目录')
parser.add_argument('--file',help='输入.md文件的路径')
def handle(self, *args, **options):
inputfile = input('请输入指定的目录路径或.md文件路径:')
if inputfile.find('.md') > 0:
self.transblogbyfile(inputfile)
else:
self.transblogbypath(inputfile)
if options['path']:
self.transblogbypath(options['path'])
if options['file']:
self.transblogbyfile(options['file'])
'''读取目录解析md文件并写入数据库'''
def transblogbypath(self,filepath='',):
try:
files = os.listdir(filepath)
for file in files:
if file.find('.md') > 0:
blog_file = os.path.join(filepath, file)
self.transblogbyfile(blog_file)
except FileNotFoundError as e:
print('请确认输入是否正确。',e)
'''读取md文件入库'''
def transblogbyfile(self,blogfile=''):
blog_info = parseblog(blogfile)
filename=os.path.basename(blogfile)
#判断是否存在相同的title
qs=BlogPost.objects.filter(title=blog_info['title'])
if len(qs)==0:
category = None
tag_objs = []
if 'categories' in blog_info:
categories=blog_info['categories']
if len(categories)>0:
category_title = categories[0]
category_qs=BlogCategory.objects.filter(title=category_title)
if len(category_qs)>0:
category=category_qs[0]
if 'tags' in blog_info:
tags=blog_info['tags']
for tag in tags:
tag_obj,b=Tag.objects.get_or_create(tag=tag)
print(tag_obj.id)
tag_objs.append(tag_obj)
blog = BlogPost()
blog.title = blog_info['title']
blog.content = blog_info['content']
blog.isShow = 1 #默认显示
blog.summary=blog.content[0:200] #默认提取内容的前200个字作为摘要
blog.category=category
blog.blogSource = filename
blog.pubTime=blog_info['date']
blog.save()
if len(tag_objs)>0:
blog.tags.add(*tag_objs)
print(filename + '读取解析入库成功!')
else:
print(blog_info['title']+'已经存在!')
代码很简单,就是根据读取命令行的参数,这个参数就是需要迁移hexo的.md文件的目录或文件路径,读取目录或文件路径进行文件的解析,并写入到数据库。 .md文件的解析参考:Python二十行代码实现hexo的md文件格式解析
三、测试验证
命令代码写完后就可以进行测试了。
在命令行输入python manage.py 可以看到自定义的transblog已经加入到管理命令了

输入 python manage.py transblog -h
会提示命令的参数和用法:

如执行 python manage.py transblog 会提示"请输入指定的目录路径或.md文件路径:"
(venv) PS D:\Python\study\pythonproject\ishareblog\ishareblog> python manage.py transblog
请输入指定的目录路径或.md文件路径:
我们输入需要迁移的.md文件或路径
如:E:\CloudStation\personal\xiejavablog\myhexo\myblog\source_posts\2022-07-27-Python二十行代码实现hexo的md文件格式解析.md
不出意外的情况下控制台会打印“XXXX.md读取解析入库成功!”的信息

访问博客,可以看到文章已经迁移过来了
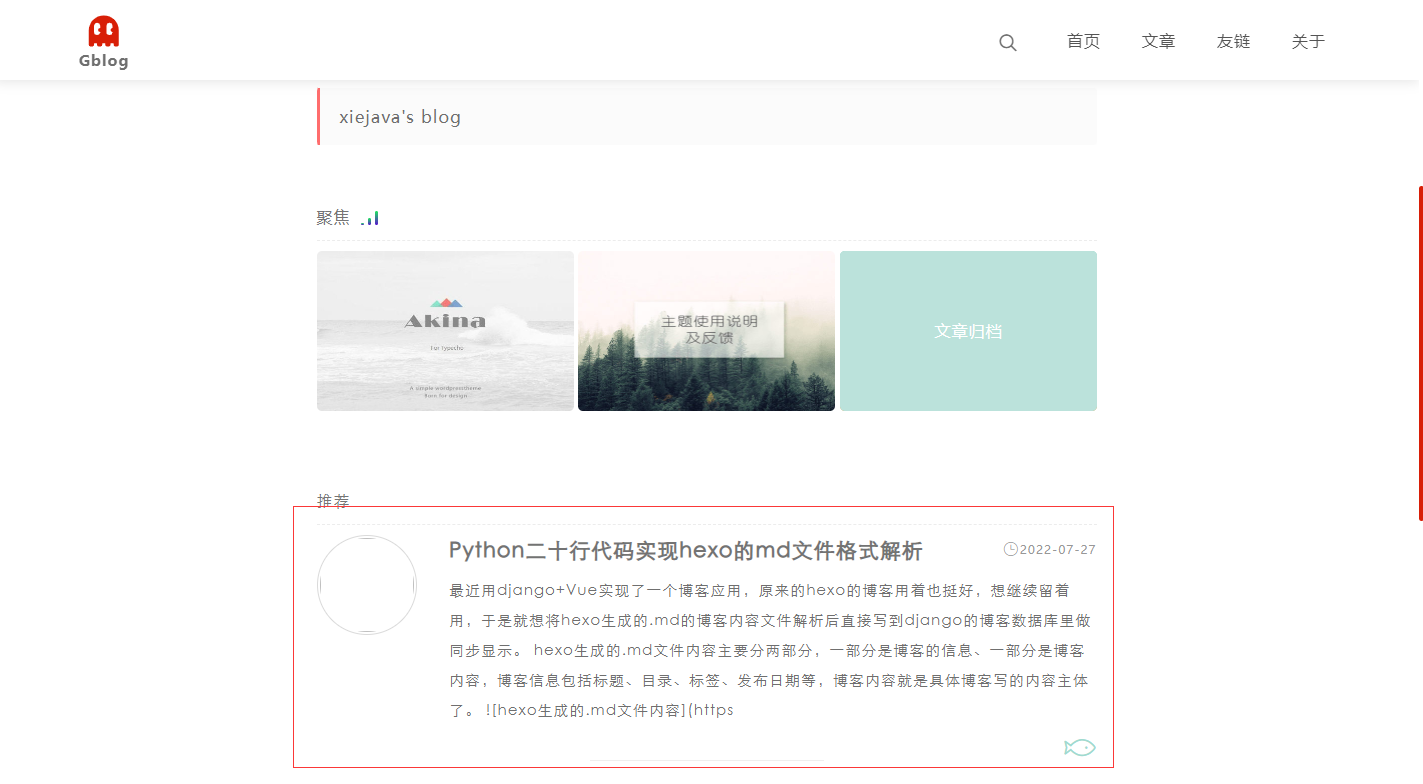 全部代码仓库:https://gitee.com/ishareblog/ishareblog
全部代码仓库:https://gitee.com/ishareblog/ishareblog
作者博客:http://xiejava.ishareread.com/

关注微信公众号,一起学习、成长!