
logstash是一个非常灵活好用的数据采集框架工具,可以通过简单的配置满足绝大多数数据采集场景的需求。
采集数据一个非常典型的场景就是将数据先放到kafka队列里削峰,然后从kafka队列里读取数据到mysql或其他存储系统中进行保存。
 本文通过一个简单的示例来演示从syslog采集日志到kafka然后在从kafka写到mysql数据库中。
默认已经安装好了kafka、mysql、logstash,并已经经过简单的验证。
本文通过一个简单的示例来演示从syslog采集日志到kafka然后在从kafka写到mysql数据库中。
默认已经安装好了kafka、mysql、logstash,并已经经过简单的验证。
准备logstash的环境
一、下载mysql的jdbc驱动包
下载地址:https://mvnrepository.com/artifact/mysql/mysql-connector-java/8.0.15 下载后放到logstash的安装目录的/vendor/jar/目录下
二、安装logstash插件
logstash默认安装了kafka插件,但是mysql插件没有默认安装需要自己安装。 具体安装方法 /bin/logstash-plugin install logstash-output-jdbc ,这里应为要用到logstash写入mysql数据库,所以安装的插件是logstash-output-jdbc,如果要用到从mysql读数据,那么就要安装logstash-input-jdbc。安装方法类似。 因为安装时需要访问国外的源,安装进度很慢很慢,还经常安装不成功,所以需要更改国内的源。 也就是给 Ruby 换成国内的镜像站:https://gems.ruby-china.com/,替代https://rubygems.org。请注意:国内的镜像站从https://gems.ruby-china.org 换成了 https://gems.ruby-china.com !!! 现在很多网上的资料就都是写的https://gems.ruby-china.org,导致很多人换了镜像源也装不上。 具体方法如下:
1. 安装Gem并更新
# yum install -y gem
# gem -v
2.0.14.1
# gem update --system
# gem -v
2.7.7
2. 检查并修改镜像源
# gem sources -l
*** CURRENT SOURCES ***
https://rubygems.org/
# gem sources --add https://gems.ruby-china.com/ --remove https://rubygems.org/
https://gems.ruby-china.org/ added to sources
https://rubygems.org/ removed from sources
# cat ~/.gemrc
---
:backtrace: false
:bulk_threshold: 1000
:sources:
- https://gems.ruby-china.org/
:update_sources: true
:verbose: true
请注意:国内的镜像站从https://gems.ruby-china.org 换成了 https://gems.ruby-china.com !!!现在很多网上的资料就都是写的https://gems.ruby-china.org,导致很多人换了镜像源也装不上。
3. 修改 logstash的 gem 镜像源
cd到logstach的安装目录,可以看到Gemfile文件
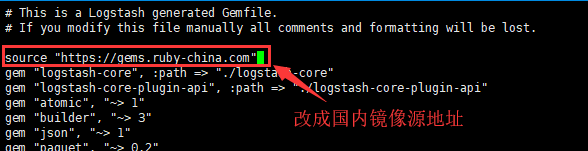
# vi Gemfile
# This is a Logstash generated Gemfile.
# If you modify this file manually all comments and formatting will be lost.
source "https://rubygems.org"
gem "logstash-core", :path => "./logstash-core"
......
更改默认的 https://rubygems.org 为https://gems.ruby-china.com
4. 安装 logstash-output-jdbc
#/bin/logstash-plugin install logstash-output-jdbc
Validating logstash-output-jdbc
Installing logstash-output-jdbc
Installation successful
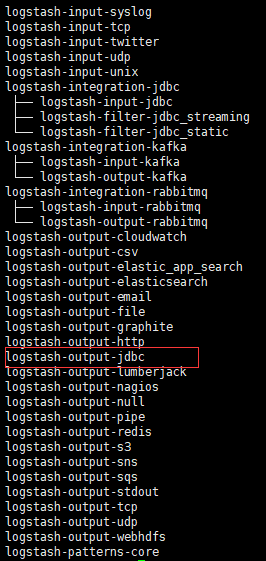
5.查看插件是否安装成功
在logstash的bin目录下执行./logstash-plugin list 可以查看已经安装的插件,可以看到logstash-output-jdbc的插件已经装好。
配置logstash
新建一个pipline.conf的配置文件
vi test-pipeline.conf
文件内容如下:
input {
stdin{ #用于测试标准控制台输入的数据
type => "test-log"
}
syslog{ #用于接收来自syslog的日志
type => "test-log"
port => 514
}
kafka {
bootstrap_servers => "172.28.65.26:9092" #kafka服务器地址
topics => "test1" #kafka订阅的topic主题
codec => "json" #写入的时候使用json编码,因为logstash收集后会转换成json格式
consumer_threads => 1
decorate_events => true
add_field => {
"logsource" => "kafkalog"
}
}
}
output
{
if ([type]=="test-log" and "kafkalog" not in [logsource]) {
kafka {
codec => json
topic_id => "test1"
bootstrap_servers => "172.28.65.26:9092"
batch_size => 1
}
}
if ([type] == "test-log" and "kafkalog" in [logsource]) {
jdbc {
driver_jar_path => "/opt/elk/logstash-7.6.0/vendor/jar/jdbc/mysql-connector-java-8.0.15.jar"
driver_class => "com.mysql.jdbc.Driver"
connection_string => "jdbc:mysql://172.28.65.32:3306/testdb?user=yourdbuser&password=yourpassword"
statement => [ "INSERT INTO test_nginx_log (message) VALUES(?)", "message"]
}
}
stdout {
codec => rubydebug
}
}
这个逻辑就是从stdin或syslog接收数据output到kafka,然后从kafka中取出数据加入了一个logsource的字标识是从kafka过来的数据,然后又output到 jdbc写到mysql中去。 如果没有这几个if的逻辑判断,那么就会是个死循环。从kafka读同样的数据又写到kafka中。如果在两台机器上装有logstash一台取数据放到kafka,一台从kafka中取数据放到mysql中就可以不用加这样的判断逻辑会单纯简单一些。
执行logstash并查看效果
通过在logstash安装目录下执行 bin/logstash -f test-pipeline.conf --config.test_and_exit 检查配置文件是否有问题,没有问题以后执行bin/logstash -f test-pipeline.conf --config.reload.automatic 运行logstash。 在控制台输入
this is a test!
效果:
从控制台输入信息,可以看到从stdin输入output到stdout的没有logsource标识,input从kafka订阅过来的信息加了一个logsource=>kafkalog的标识。
 用kafka tool工具看到kafka收到了从stdin发过来的信息。
用kafka tool工具看到kafka收到了从stdin发过来的信息。
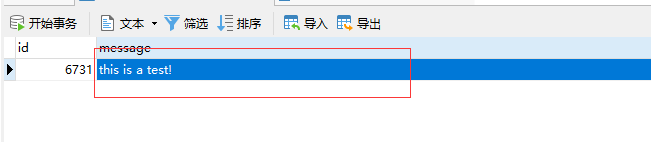
 在看MySQL表里的数据,已经通过logstash从kafka中将数据采集到了MySQL的表中。
在看MySQL表里的数据,已经通过logstash从kafka中将数据采集到了MySQL的表中。
 再来看从syslog采集日志的效果
从控制台看到的信息效果
再来看从syslog采集日志的效果
从控制台看到的信息效果
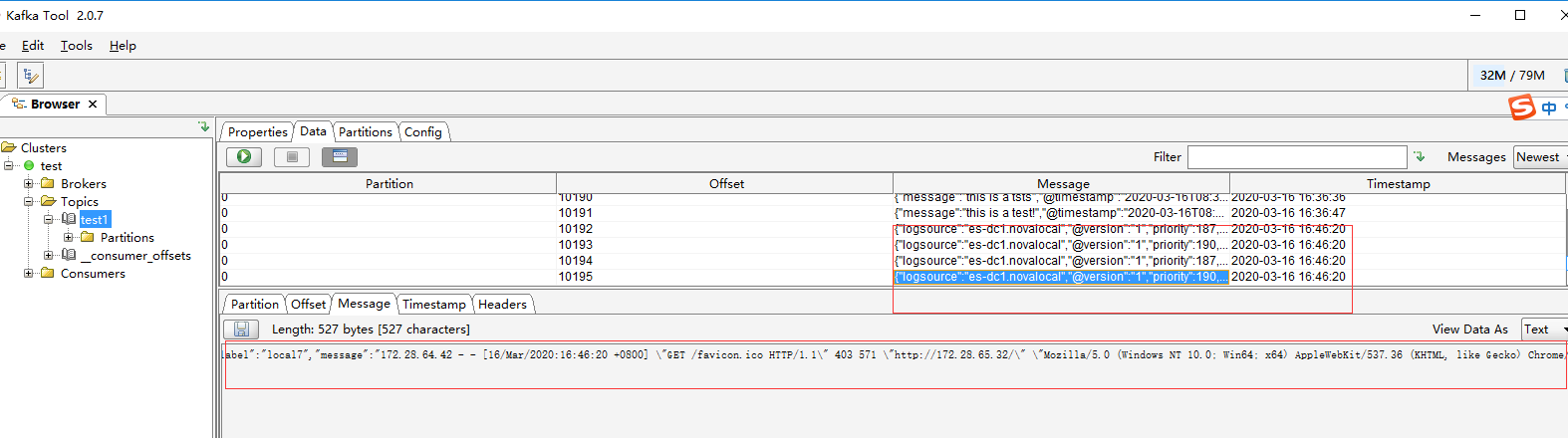
 从kafka tool看到的效果
从kafka tool看到的效果
 从mysql 表中看到的效果。
从mysql 表中看到的效果。
 可以看到,logstash是一个非常灵活好用的数据采集框架工具,可以通过简单的配置就能满足绝大多数数据采集场景的需求。
可以看到,logstash是一个非常灵活好用的数据采集框架工具,可以通过简单的配置就能满足绝大多数数据采集场景的需求。
作者博客:http://xiejava.ishareread.com

关注:微信公众号,一起学习成长!