
最近在学习Python,相对java来说python简单易学、语法简单,工具丰富,开箱即用,适用面广做全栈开发那是极好的,对于小型应用的开发,虽然运行效率慢点,但开发效率极高。大大提高了咱们的生产力。为什么python能够在这几年火起来,自然有他的道理,当然也受益于这几年大数据和AI的火。
据说网络上80%的爬虫都是用python写的,不得不说python写爬虫真的是so easy。基本上一个不太复杂的网站可以通过python用100多行代码就能实现你所需要的爬取。 现在就以一个电子书的网站为例来实现python爬虫获取电子书资源。爬取整站的电子书资源,按目录保存到本地,并形成索引文件方便查找。
爬取的目标网站:苦瓜书盘
步骤:爬取->分析、解析->保存
对于一个不需要登录验证的资源分享类的网站,爬取最大的工作量应该是在对目标页面的分析、解析、识别,这里用的到是Python的BeautifulSoup库。
一、获取目录
二、获取书籍列表页
三、获取书籍详情页
四、分析书籍详情页的资源地址
五、下载并保存
准备
引入相应的包,设置 headerd, 和资源保存路径
import requests
import os
import re
from bs4 import BeautifulSoup
import time
import json
from Book import Book
savepath="J://kgbook//books//" #保存地址
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'
}
main_url='https://kgbook.com/'
bookcount=0
一、获取目录
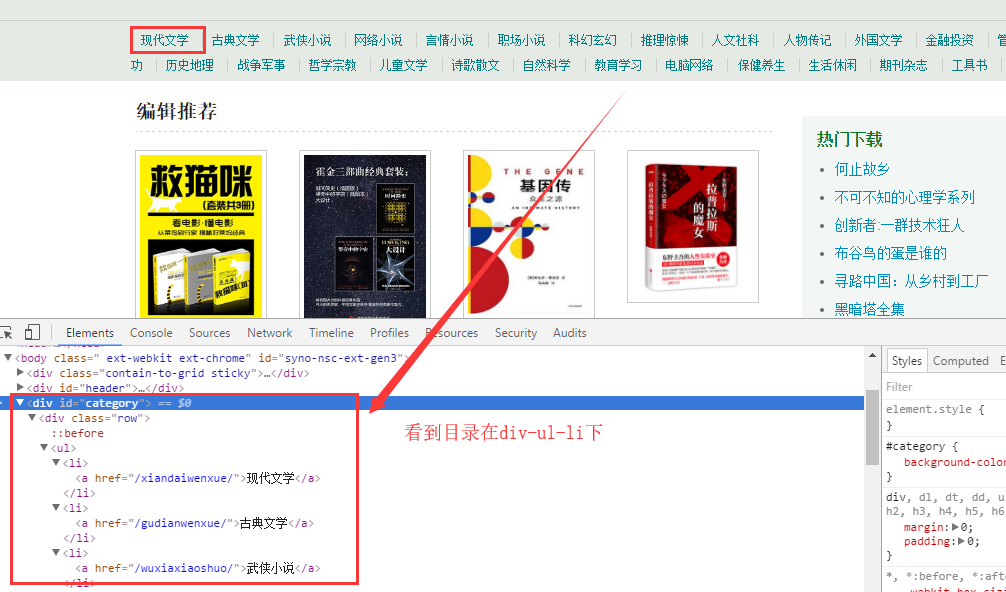 通过浏览器的调试工具可以看到目录在id=catagory的div标签下,下面还有ul和li标签,那我们可以迭代li可以获得目录及目录页的地址。
可以通过soup.find_all(attrs={'id': 'category'})[0].ul 获取 到ul标签,然后获取ul的li标签,进行迭代获取。
代码如下:
通过浏览器的调试工具可以看到目录在id=catagory的div标签下,下面还有ul和li标签,那我们可以迭代li可以获得目录及目录页的地址。
可以通过soup.find_all(attrs={'id': 'category'})[0].ul 获取 到ul标签,然后获取ul的li标签,进行迭代获取。
代码如下:
'''
获取目录
'''
def getcategory():
req_result=requests.get(main_url,headers=headers)
if req_result.status_code==200:
htmlstr=req_result.content.decode('utf-8')
soup = BeautifulSoup(htmlstr, 'lxml')
categorys=soup.find_all(attrs={'id': 'category'})[0].ul
for li in categorys.find_all(name='li'):
print('开始抓取'+li.a.attrs['href']+"--"+li.string)
getcategroydetail(main_url+li.a.attrs['href'],li.string)
time.sleep(1)
二、获取书籍列表页
在书籍列表页,我们要获取两个信息,分别是书籍列表的信息及翻页下一页书籍列表的URL地址。
通过浏览器的调试工具分别对列表的信息及翻页下一页的html进行分析。
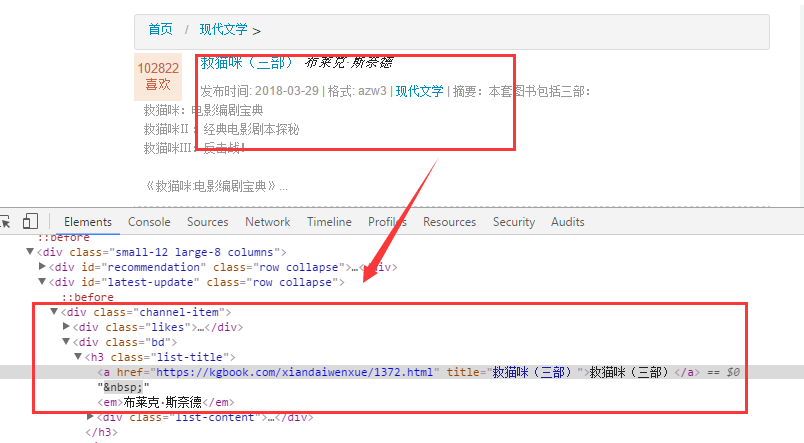 列表中的书籍详情页信息在class="channel-item"的div标签下,通过class="list-title"的h3标签循环迭代
列表中的书籍详情页信息在class="channel-item"的div标签下,通过class="list-title"的h3标签循环迭代
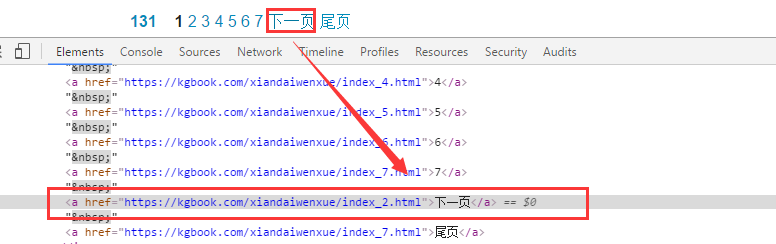 下一页,我们可以直接通过next_pag=soup.find(name='a',text=re.compile('下一页'))来获取。
然后我们可以通过递归来不断的调用获取下一页书籍列表页的代码,知道没有下一页为止。就可以把怎个目录都可以爬取完。
代码如下:
下一页,我们可以直接通过next_pag=soup.find(name='a',text=re.compile('下一页'))来获取。
然后我们可以通过递归来不断的调用获取下一页书籍列表页的代码,知道没有下一页为止。就可以把怎个目录都可以爬取完。
代码如下:
'''
获取书籍列表
'''
def getbookslist(bookurlstr,categroy_path):
book_result=requests.get(bookurlstr,headers=headers)
bookhtmlstr=book_result.content.decode('utf-8')
soup = BeautifulSoup(bookhtmlstr, 'lxml')
booklists=soup.select('.channel-item')
for bookinfo_div in booklists:
booktitle_div=bookinfo_div.select('.list-title')[0]
bookurl=booktitle_div.a.attrs['href']
getbookdetail(bookurl,categroy_path)
next_pag=soup.find(name='a',text=re.compile('下一页'))
if next_pag is not None:
next_url=next_pag.attrs['href']
print('爬取下一页:'+next_url)
getbookslist(next_url,categroy_path)
三、获取书籍详情页
我们要在书籍详情页需要获得书籍详情信息包括书名、作者等信息
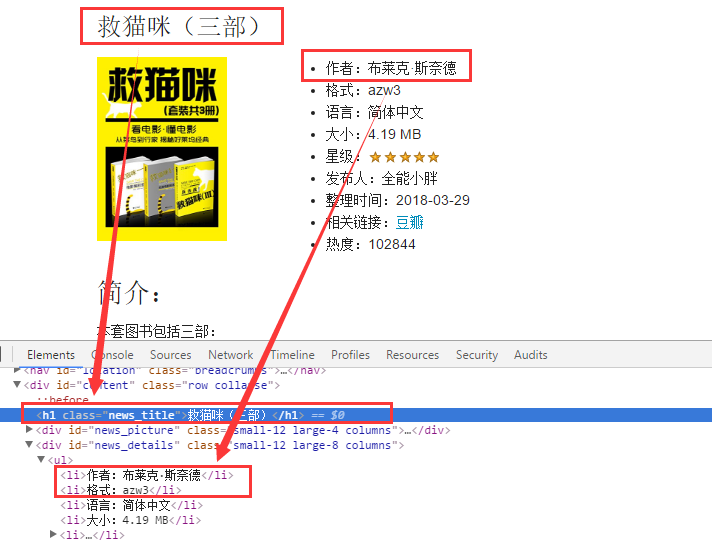 关于书名和作者可以分别通过提取class="news_title"的h1标签和id="news_details"的div下的ul下的li再通过正则表达式对作者信息进行提取。
关于书名和作者可以分别通过提取class="news_title"的h1标签和id="news_details"的div下的ul下的li再通过正则表达式对作者信息进行提取。
booktitle=bookdetailsoup.select('.news_title')[0].text.strip()
bookauthor=bookdetailsoup.select('#news_details')[0].ul.li.find(text=re.compile('作者:(.*?)')).strip()
bookauthor=bookauthor.replace('作者:','')
booktitleinfo="《"+booktitle+'》-'+bookauthor
四、分析书籍详情页的资源地址
在书籍详情页,我们还要分析书籍详情页的资源地址
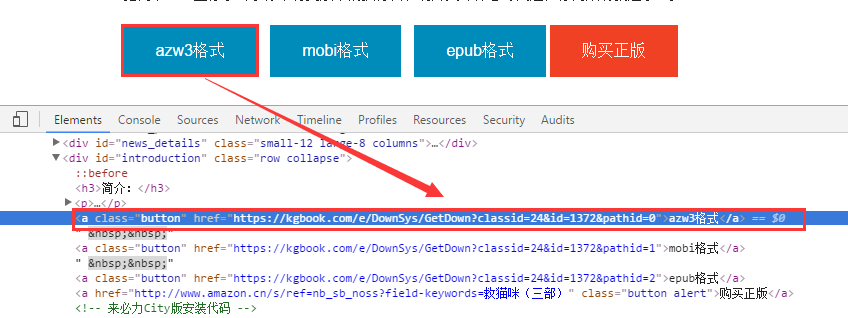 电子书的资源下载地址可以通过提取a标签的信息来获取。通过正则表达式分别匹配azw3、mobi、epub分别提取不同的电子书资源。
book_url_item=bookdetailsoup.find(name='a',text=re.compile(booktype,re.I))
代码如下:
电子书的资源下载地址可以通过提取a标签的信息来获取。通过正则表达式分别匹配azw3、mobi、epub分别提取不同的电子书资源。
book_url_item=bookdetailsoup.find(name='a',text=re.compile(booktype,re.I))
代码如下:
'''
根据书籍资源类型下载资源
'''
def getbookfortype(bookurl,categroy_path,bookdetailsoup,booktype):
booktitle=bookdetailsoup.select('.news_title')[0].text.strip()
bookauthor=bookdetailsoup.select('#news_details')[0].ul.li.find(text=re.compile('作者:(.*?)')).strip()
bookauthor=bookauthor.replace('作者:','')
booktitleinfo="《"+booktitle+'》-'+bookauthor
print('书籍详情:---'+booktitleinfo)
book_url_item=bookdetailsoup.find(name='a',text=re.compile(booktype,re.I))
if book_url_item is not None:
downloadurl=book_url_item.attrs['href']
print('下载地址:'+downloadurl)
if checkIfNoExistBookByUrl(downloadurl):
r = requests.get(downloadurl)
if r.status_code==200:
savepath=createdir(categroy_path,booktitleinfo)
filename=booktitle+"."+booktype
savebook(r.content,savepath,filename)
p,f=os.path.split(categroy_path)
bookcategory=f
book=Book(bookcategory,booktitle,bookauthor,bookurl,downloadurl,savepath,"苦瓜书盘",booktype)
print(book.toString())
savebooktojson(book)
else:
print('下载失败:status_code='+str(r.status_code))
else:
print('没有'+booktype+'格式的书')
五、下载并保存 有了资源的下载资源后下载就变得很简单了,主要用python的os库,对文件进行操作,包括建目录及保存资源文件。也可以通过连接数据库将爬取的数据保存到数据库。 定义书籍类Book用于组织和保存数据。
class Book(object):
def __init__(self,bookcategory,bookname,bookauthor,bookurl,bookdownloadurl,booksavepath,booksource,booktype):
self.bookcategory=bookcategory
self.bookname=bookname
self.bookauthor=bookauthor
self.bookurl=bookurl
self.bookdownloadurl=bookdownloadurl
self.booksavepath=booksavepath
self.booksource=booksource
self.booktype=booktype
def toString(self):
return {"bookcategory":self.bookcategory,"bookname":self.bookname,"bookauthor":self.bookauthor,"bookurl":self.bookurl,"bookdownloadurl":self.bookdownloadurl,"booksavepath":self.booksavepath,"booksource":self.booksource,"booktype":self.booktype}
'''
将获取的信息保存至文件
'''
def savebooktojson(book):
bookdata={
'booksource':book.booksource,
'booktype':book.booktype,
'bookcategory':book.bookcategory,
'bookname':book.bookname,
'bookauthor':book.bookauthor,
'bookurl':book.bookurl,
'bookdownloadurl':book.bookdownloadurl,
'booksavepath':book.booksavepath
}
bookjson=json.dumps(bookdata,ensure_ascii=False) #ensure_ascii=False 就不会用 ASCII 编码,中文就可以正常显示了
print(bookjson)
with open('data.json', 'a',encoding='gbk') as file:
file.write(bookjson+'\n')
'''
根据目录创建文件夹
'''
def createdir(savepath,dir):
path=os.path.join(savepath,dir)
isExists=os.path.exists(path)
if isExists:
print('已经存在'+dir)
else:
print('创建目录'+dir)
os.mkdir(path)
return path
'''
下载书籍资源
'''
def savebook(content,savepath,savefilename):
savefile=os.path.join(savepath,savefilename)
with open(savefile, "wb") as code:
code.write(content)
运行效果如下:
1、爬取过程
 2、爬取记录的json信息
data.json的信息如下:
2、爬取记录的json信息
data.json的信息如下:
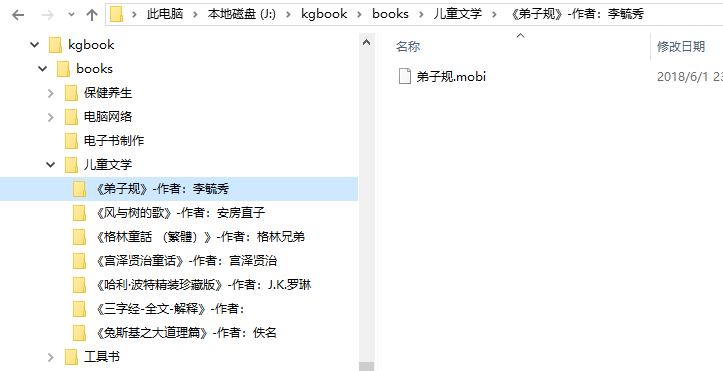
 3、爬取获取的资源
按目录都已经整理好了,够你看的了。
3、爬取获取的资源
按目录都已经整理好了,够你看的了。
Python爬虫获取电子书资源实战的全部代码,包括爬取->分析、解析->保存至本地及数据库。下载
github: https://github.com/xiejava1018/getbooks
博客:http://xiejava.ishareread.com/

关注:微信公众号,一起学习成长!