
快过年了,又到了公司年底评级的时候了。今年的评级和往常一下,每个人都要填写公司的民主评议表,给各个同事进行评价打分,然后部门收集起来根据收集上来的评价表进行汇总统计。想想要收集几十号人的评价表,并根据每个人的评价表又要填到Excel中进行汇总计算统计给出每个人的评价,就头大。虽然不是个什么难事,但是是个无脑的细致活。几十个人的评价也得要花大半天的时间来弄,而且搞多了还容易搞错。如是就想起干脆用Python写个小程序自动来处理这些脏活累活,评级年年都要评,每年都可以用。
要做的事情就是读放到某个文件夹中的word文档中的评价表格,根据表格内容进行处理,然后汇总所有的表格数据,根据计算规则,算出每个人的评分,在根据评分计算每个人的评价。汇总后写入Excel中。
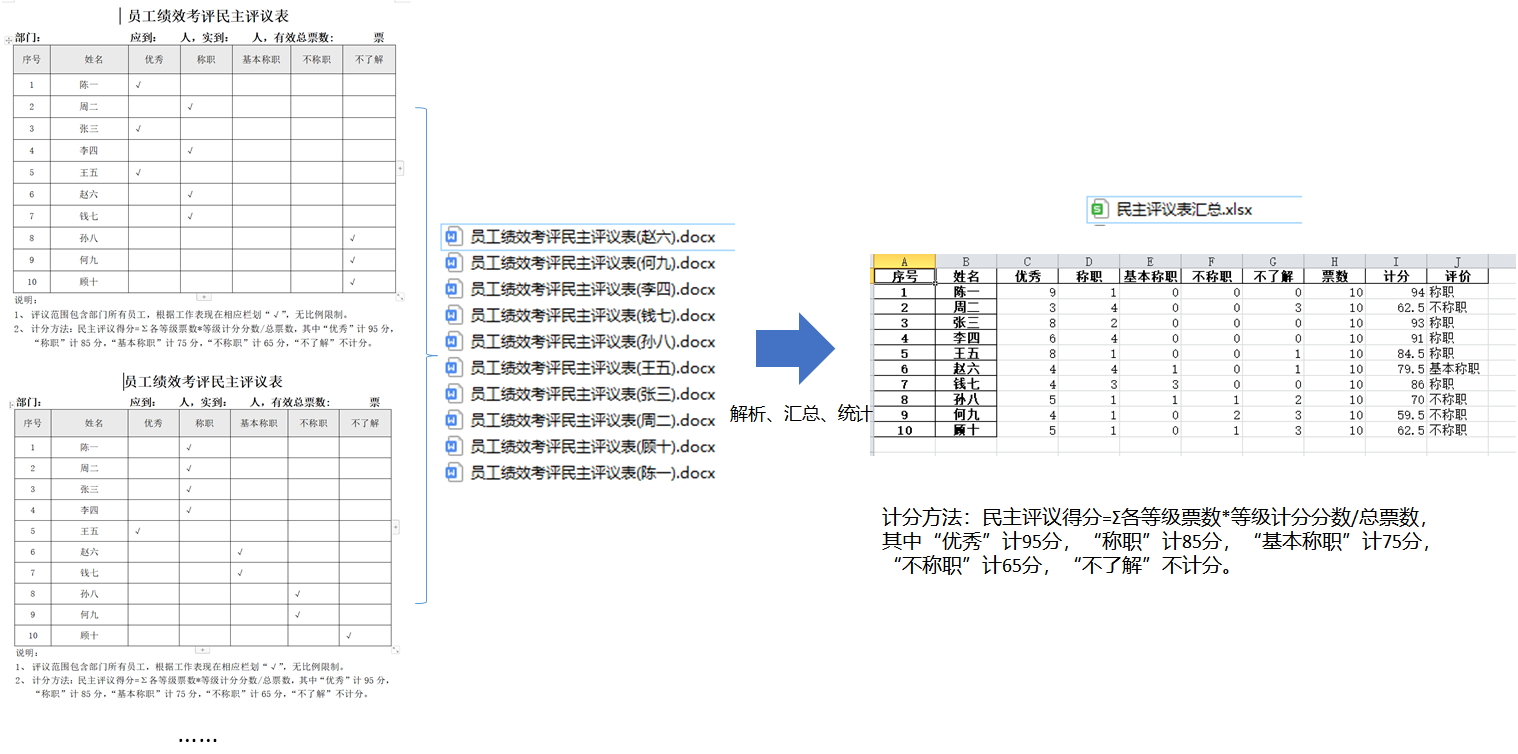
不可否认用Python来实现这样的事情真的是太方便了,人生苦短我用Python。 我是用的python的docx包来处理word,用pandas来处理数据并写入excel
一、首先导入包
pip install docx
pip install pandas
pandas写excel依赖openpyxl包所以也到导入
pip install openpyxl
二、读评价表所在的目录文件
通过python的os包,列出文件夹里面的文件,识别出.docx的文件
files=os.listdir(filepah)
for file in files:
if file.find('.docx')>0:
docfilepah=filepah+file
三、读word文件,处理word中的表格数据
data=[]
#读word的docx评议表文件,并读取word中的表格数据
def procdoc(docfilepath):
document=Document(docfilepath)
tables=document.tables
table=tables[0]
for i in range(1,len(table.rows)):
id=int(table.cell(i,0).text)
name=table.cell(i,1).text
excellent=0
if table.cell(i,2).text!='' and table.cell(i,2).text is not None:
excellent=1
competent = 0
if table.cell(i, 3).text!='' and table.cell(i, 3).text is not None:
competent=1
basicacompetent=0
if table.cell(i, 4).text!='' and table.cell(i, 4).text is not None:
basicacompetent=1
notcompetent = 0
if table.cell(i, 5).text!='' and table.cell(i, 5).text is not None:
notcompetent=1
dontunderstand =0
if table.cell(i, 6).text!='' and table.cell(i, 6).text is not None:
dontunderstand=1
appraisedata=[id,name,excellent,competent,basicacompetent,notcompetent,dontunderstand]
data.append(appraisedata)
四、统计计算
通过pandas直接对数据进行统计计算,避免了传统的循环计算。
df = pd.DataFrame(data,columns=['序号','姓名','优秀','称职','基本称职','不称职','不了解'])
df=df.groupby(['序号','姓名']).sum() #汇总每个人每一项的评分
df['票数'] = df.apply(lambda x: x.sum(), axis=1) #统计票数
df['计分'] = (df['优秀']*95+df['称职']*85+df['基本称职']*75+df['不称职']*65+df['不了解']*0)/len(df)#根据规则计分
df['评价']=df['计分'].map(getscore) #根据规则评价评级
计分方法:民主评议得分=Σ各等级票数*等级计分分数/总票数,其中“优秀”计95分,“称职”计85分,“基本称职”计75分,“不称职”计65分,“不了解”不计分。
#根据评分规则计算评级
def getscore(x):
if x>=95:
score='优秀'
elif x>=80 and x<95:
score='称职'
elif x>=75 and x<80:
score='基本称职'
elif x<75:
score='不称职'
return score
五、将统计计算结果写入汇总Excel
通过pandas直接可以将dataframe写入到Excel文件
#将汇总计算好的数据写入Excel
def write2excle(exclefile,dataframe):
writer = pd.ExcelWriter(exclefile)
dataframe.to_excel(writer)
writer.save()
print('输出成功')
完整代码
Python不到八十行代码,实现读Word->处理表格数据->汇总计算数据->写Excel。 完整的代码如下:
import os
import pandas as pd
from docx import Document
data=[]
#读word的docx评议表文件,并读取word中的表格数据
def procdoc(docfilepath):
document=Document(docfilepath)
tables=document.tables
table=tables[0]
for i in range(1,len(table.rows)):
id=int(table.cell(i,0).text)
name=table.cell(i,1).text
excellent=0
if table.cell(i,2).text!='' and table.cell(i,2).text is not None:
excellent=1
competent = 0
if table.cell(i, 3).text!='' and table.cell(i, 3).text is not None:
competent=1
basicacompetent=0
if table.cell(i, 4).text!='' and table.cell(i, 4).text is not None:
basicacompetent=1
notcompetent = 0
if table.cell(i, 5).text!='' and table.cell(i, 5).text is not None:
notcompetent=1
dontunderstand =0
if table.cell(i, 6).text!='' and table.cell(i, 6).text is not None:
dontunderstand=1
appraisedata=[id,name,excellent,competent,basicacompetent,notcompetent,dontunderstand]
data.append(appraisedata)
#读取评议表的目录,并处理目录中的docx文件,根据评议表计算评分,写入汇总表。
def readfile(filepah):
files=os.listdir(filepah)
for file in files:
if file.find('.docx')>0:
docfilepah=filepah+file
procdoc(docfilepah)
df = pd.DataFrame(data,columns=['序号','姓名','优秀','称职','基本称职','不称职','不了解'])
print(df)
df=df.groupby(['序号','姓名']).sum()
df['票数'] = df.apply(lambda x: x.sum(), axis=1)
df['计分'] = (df['优秀']*95+df['称职']*85+df['基本称职']*75+df['不称职']*65+df['不了解']*0)/len(df)
df['评价']=df['计分'].map(getscore)
print(df)
write2excle('民主评议\\民主评议表汇总.xlsx',df)
#根据评分规则计算评级
def getscore(x):
if x>=95:
score='优秀'
elif x>=80 and x<95:
score='称职'
elif x>=75 and x<80:
score='基本称职'
elif x<75:
score='不称职'
return score
#将汇总计算好的数据写入Excel
def write2excle(exclefile,dataframe):
writer = pd.ExcelWriter(exclefile)
dataframe.to_excel(writer)
writer.save()
print('输出成功')
if __name__ == '__main__':
readfile('民主评议\\')
全部源代码:https://github.com/xiejava1018/pythonprocword
作者博客:http://xiejava.ishareread.com/

关注:微信公众号,一起学习成长!