
对于数据分析来说,在构造或载入数据后最基本的操作应该就是对数据的访问了。看一看数据的结构、组成、分布等,根据需要从数据集中检索提取出相应的数据。pandas作为数据分析的利器,当然提供了多种查看和检索数据的方法。本文就来捋一捋pandas基本的数据访问。
一、查看数据
当我们拿到数据集后,第一步可能就是查看数据了,一方面是了解拿到的数据集的数据结构,另一方面随机检查一下数据的质量问题。 不管是Series还是DataFrame的数据集pandas常用的数据查看方法有:
| 方法 | 操作 | 结果 |
|---|---|---|
| head(n) | 查看数据集对象的前n行 | Series或DataFrame |
| tail(n) | 查看数据集的最后n行 | Series或DataFrame |
| sample(n) | 随机查看n个样本 | Series或DataFrame |
| describe() | 数据集的统计摘要 | Series |
以下就以一个DataFrame数据集为例来看看这些查看数据的方法。
import numpy as np
import pandas as pd
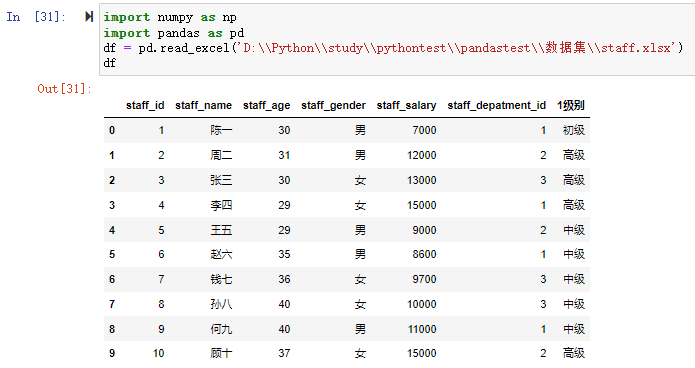
df = pd.read_excel('D:\\Python\\study\\pythontest\\pandastest\\数据集\\staff.xlsx')
df
1、查看头部 head(n)
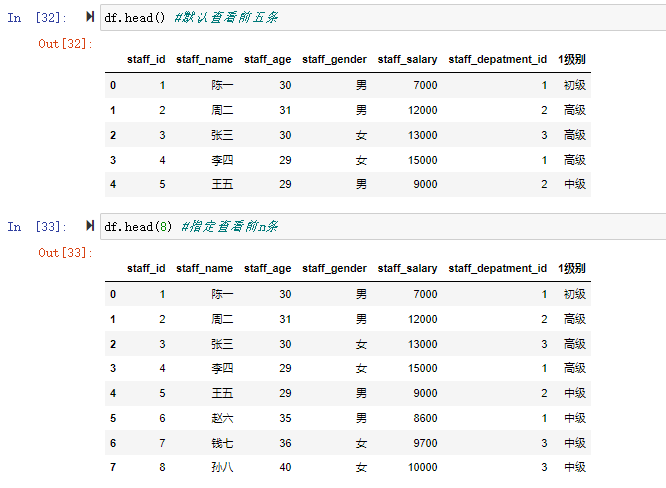
head()方法如果不带参数,默认返回前5条记录,带了参数n就返回前n条记录。
df.head() #默认查看前5条记录
df.head(8) #指定查看前8条记录
2、查看尾部 tail(n)
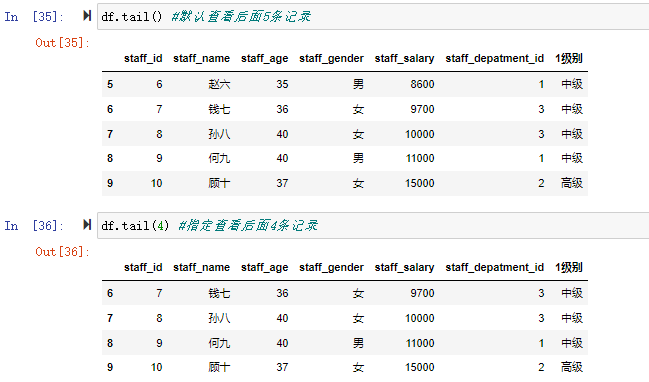
同样tail()方法如果不带参数,默认返回后面5条记录,带了参数n就返回后面n条记录。
df.tail() #默认查看后面5条记录
df.tail(4) #指定查看后面4条记录
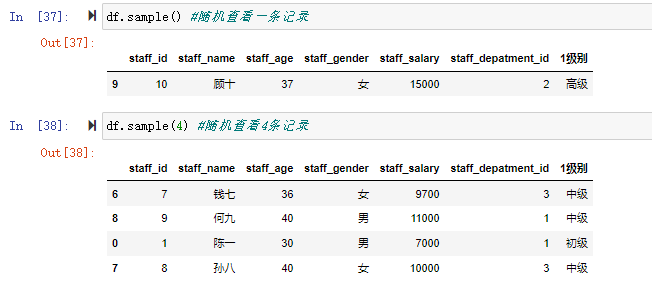
3、随机查看样本 sample(n)
sample() 不带参数会随机返回一条样本数据,带了参数n就会随机返回n条记录。
df.sample() #随机查看一条记录
df.sample(4) #随机查看4条记录
4、查看统计摘要
df.describe() 返回所有数字列的统计摘要。
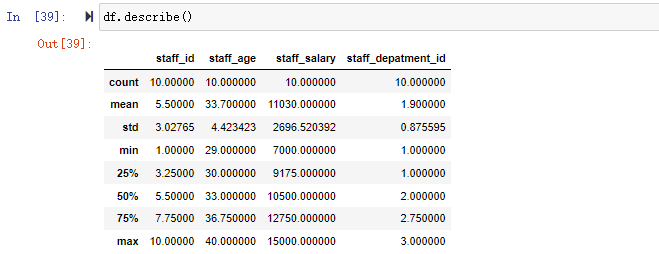
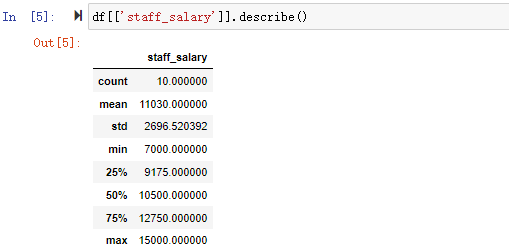
这里连staff_id的统计摘要就显示出来了,因为它是数字列。如果只看某一列的统计摘要
df[['staff_salary']].describe()
二、检索数据
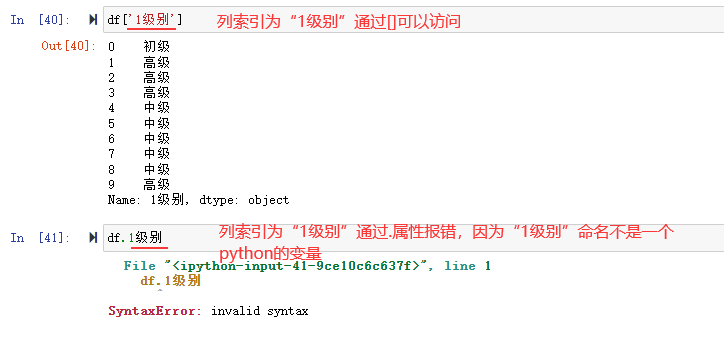
在数据分析过程中,很多时候需要从数据表中提取出相应的数据,而这么做的前提是需要先“检索”出这一部分数据。虽然通过 Python 提供的索引操作符"[]"和属性操作符"."可以访问 Series 或者 DataFrame 中的数据,但这种方式只适应与少量的数据,为了解决这一问题,pandas 提供了多种类型的索引方式来实现数据的访问。包括[]、loc\iloc、at\iat、布尔索引 一般的: df['name'] #会返回本列的Series df.name #也会返回本列的Series
但是要注意,name应该是一个合法的python变量时才可以直接作为属性来使用。
如:
df['1级别']可以正常返回索引列为“1级别”的数据,而df.1级别会报错,因为"1级别"不是一个合法的python变量。
 以下通过DataFrame数据集来说明常用检索数据的方法。对于DataFrame的数据集来说要检索数据通常是确定数据所在的行和列。而确定行和列也有两种方式,一是通过标签索引来确定,二是通过数据所在的位置来确定。
一般的:
以下通过DataFrame数据集来说明常用检索数据的方法。对于DataFrame的数据集来说要检索数据通常是确定数据所在的行和列。而确定行和列也有两种方式,一是通过标签索引来确定,二是通过数据所在的位置来确定。
一般的:
| 操作 | 语法 | 返回结果 |
|---|---|---|
| 选择列 | df[col] | Series |
| 按索引选择行 | df.loc[label] | Series |
| 按位置选择行 | df.iloc[loc] | Series |
| 使用切片选择行 | df[2:5] | DataFrame |
| 用表达式筛选行 | df[bool] | DataFrame |
1、切片[]
通过[]进行检索,这将会对行进行切片
df[0:3] #通过切片检索行数据
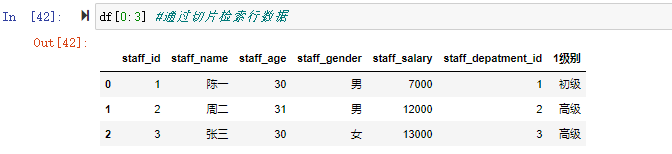
切片并不对列有效,如果是df[0:3][1:2],会检索出0-3行,再在这三行切片的基础上切片中检索出第二行。
![df[0:3][1:2]](http://image2.ishareread.com/images/2022/20220207/切片2.png)
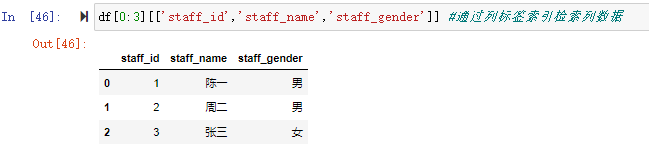
如果要在切片检索的结果上再选择列,则可以通过列标签索引列表来选择
df[0:3][['staff_id','staff_name','staff_gender']] #通过列标签索引列表检索列数据
2、loc\iloc
loc
df.loc[] 只能使用标签索引,不能使用位置索引。当通过标签索引的切片方式来筛选数据时,它的取值前闭后闭,也就是只包括边界值标签(开始和结束) .loc[] 具有多种访问方法,如下所示:
- 一个标量标签
- 标签列表
- 切片对象
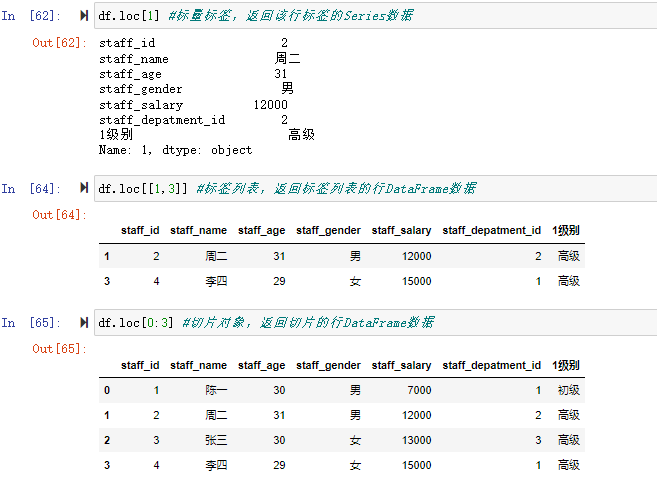
df.loc[1] #标量标签,返回该行标签的Series数据
df.loc[[1,3]] #标签列表,返回标签列表的行DataFrame数据
df.loc[0:3] #切片对象,返回切片的行DataFrame数据
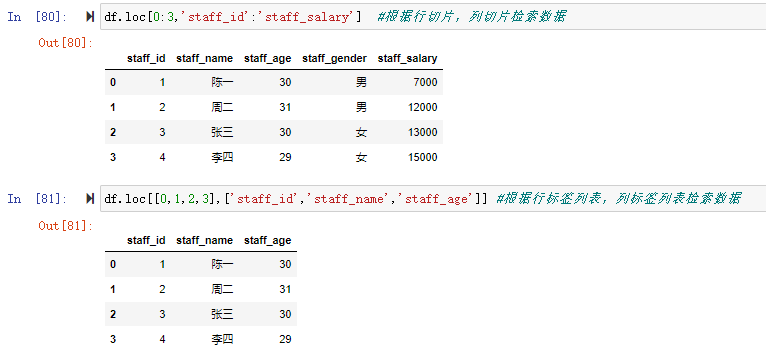
df.loc[0:3,'staff_id':'staff_salary'] #根据行切片,列切片检索数据
df.loc[[0,1,2,3],['staff_id','staff_name','staff_age']] #根据行标签列表,列标签列表检索数据
.loc[] 除了标量标签,标签列表和切片对象都接受两个参数,并以','分隔。第一个位置表示行检索,第二个位置表示列检索
iloc
df.iloc[] 只能使用位置索引(用整数表示所在行或列的位置如第几行第几列),不能使用标签索引,通过整数索引切片选择数据时,前闭后开(不包含边界结束值)。同 Python 和 NumPy 一样,它们的索引都是从 0 开始 .iloc[] 提供了以下方式来选择数据:
- 整数索引
- 整数列表
- 数值范围
为了说明方便,我们把数据集的行索引重名为字母
df=df.rename(index={0:'A',1:'B',2:'C',3:'D',4:'E',5:'F',6:'G',7:'H',8:'I',9:'J'})
df
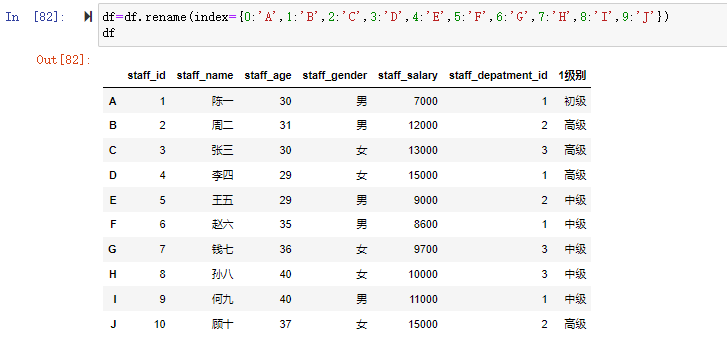
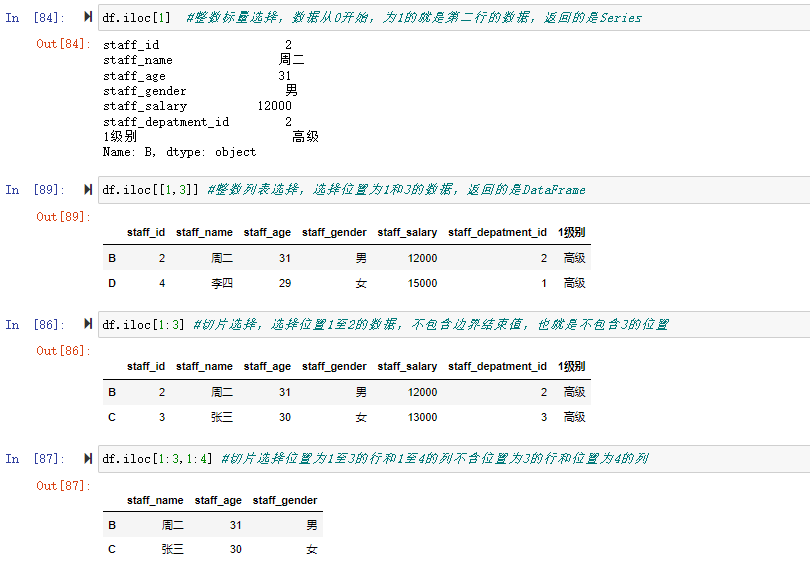
df.iloc[1] #整数标量选择,数据从0开始,为1的就是第二行的数据,返回的是Series
df.iloc[[1,3]] #整数列表选择,选择位置为1和3的数据,返回的是DataFrame
df.iloc[1:3] #切片选择,选择位置1至2的数据,不包含边界结束值,也就是不包含3的位置
df.iloc[1:3,1:4] #切片选择位置为1至3的行和1至4的列不含位置为3的行和位置为4的列
3、at\iat
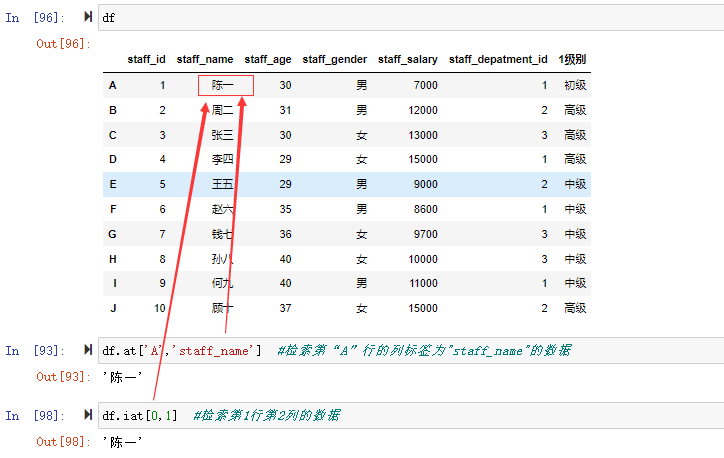
at和iat和loc和iloc类似,不同的是at和iat仅取一个具体的值,结构为 at[<索引>,<列名>],iat[<行位置>,<列位置>]
df.at['A','staff_name'] #检索第“A”行的列标签为"staff_name"的数据
df.iat[0,1] #检索第1行第2列的数据
4、布尔条件检索
1、[] 里用布尔条件进行检索
如:
df[(df.staff_salary>10000)&(df.staff_age<40)] #检索staff_age小于40且staff_salary>10000的数据
![[] 里用布尔条件进行检索](http://image2.ishareread.com/images/2022/20220207/[]条件.png)
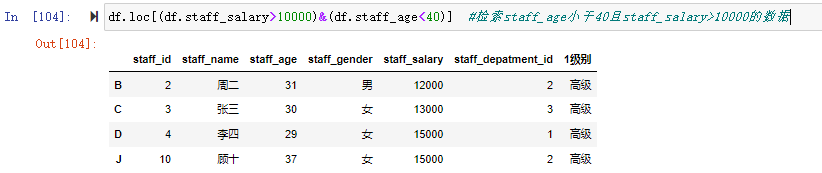
2、loc索引部分用布尔条件检索
如:
df.loc[(df.staff_salary>10000)&(df.staff_age<40)] #检索staff_age小于40且staff_salary>10000的数据
3、query函数布尔条件检索
如:
df.query('staff_salary>10000 & staff_age<40') #通过函数检索staff_age小于40且staff_salary>10000的数据
至此,本文介绍了pandas常用的数据访问操作通过head()、tail()、sample()、describe()查看数据,通过[]、loc\iloc、at\iat、及布尔条件检索数据。通过灵活运用pandas的各种数据访问方法可以很方便的根据需要查看和检索数据。
数据集及源代码见:https://github.com/xiejava1018/pandastest.git
作者博客:http://xiejava.ishareread.com/

关注:微信公众号,一起学习成长!