
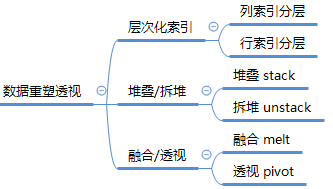
在数据分析的过程中,分析师常常希望通过多个维度多种方式来观察分析数据,重塑和透视是常用的手段。 数据的重塑简单说就是对原数据进行变形,为什么需要变形,因为当前数据的展示形式不是我们期望的维度,也可以说索引不符合我们的需求。对数据的重塑不是仅改变形状那么简单,在变形过程中,数据的内在数据意义不能变化,但数据的提示逻辑则发生了重大的改变。 数据透视是最常用的数据汇总工具,Excel 中经常会做数据透视,它可以根据一个或者多个指定的维度来聚合数据。pandas 也提供了数据透视函数来实现这些功能。 如果能熟练区分和使用各种重塑和透视分析方法,那用pandas处理分析日常的数据基本上就没有什么难度了。
在介绍数据重塑透视之前,先来介绍一下pandas中DataFrame的层次化索引,它广泛应用于重塑透视操作。
一、层次化索引
层次化索引是pandas的一项重要功能,它使你能在一个轴上拥有多个(两个以上)索引层数,分层索引的目的是用低维度的结构(Series 或者 DataFrame)更好地处理高维数据。通过分层索引,我们可以像处理二维数据一样,处理三维及以上的数据。分层索引的存在使得分析高维数据变得简单。 我们来看一下student数据集,并根据该数据集分别构建列和行的层次索引。然后再介绍数据的重塑和透视。 引入student数据集:
import numpy as np
import pandas as pd
df = pd.read_excel('D:\\Python\\study\\pythontest\\pandastest\\数据集\\student.xlsx')
df
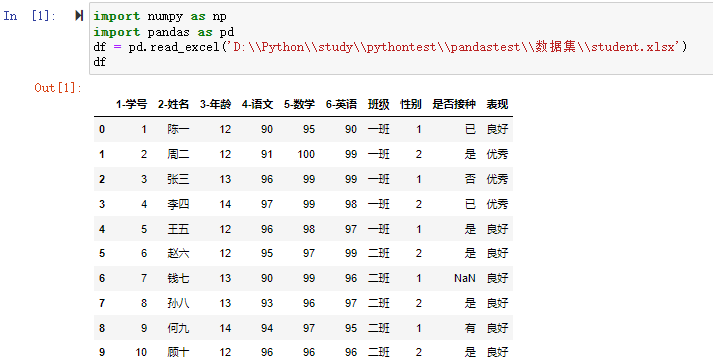
该student数据集包含学生学号、姓名、语文、数据、英语的成绩等。
1、列索引分层
我们选取一些关键的数据构建列标签的层次化索引。这里我们选取'班级','姓名','语文','数学','英语'的列,并且将‘班级’、‘姓名’标记为‘标识’,'语文','数学','英语'标记为‘成绩’
df_student=df[['班级','2-姓名','4-语文','5-数学','6-英语']]
df_student.columns=[['标识','标识','成绩','成绩','成绩'],['班级','姓名','语文','数学','英语']]
df_student
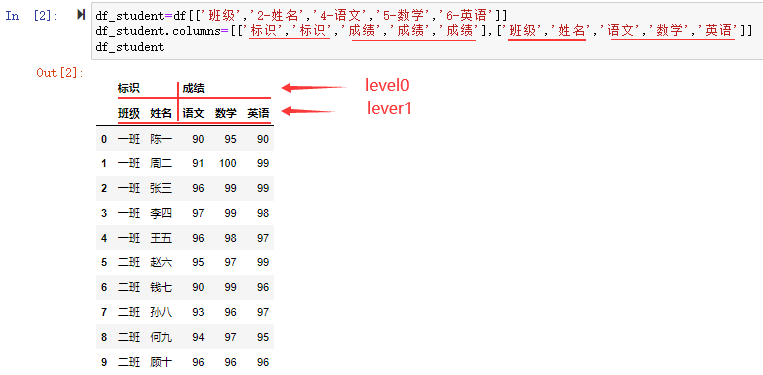 通过指定DataFrame的columns的层级将'班级','姓名','语文','数学','英语',上多抽出了一个层级,这个层有两个索引一个是‘标识’,一个是成绩,其中‘班级’和‘名称’是属于标识,'语文','数学','英语'都是'成绩'。
通过指定DataFrame的columns的层级将'班级','姓名','语文','数学','英语',上多抽出了一个层级,这个层有两个索引一个是‘标识’,一个是成绩,其中‘班级’和‘名称’是属于标识,'语文','数学','英语'都是'成绩'。
2、行索引分层
接下来看行索引的分层。我们将属于一班的和属于二班的同学进行分层,再分成两个索引。
#根据行索引分层,设置行索引将其分成班级和姓名两个层次索引
df_student=df_student.set_index([('标识','班级'),('标识','姓名')])
df_student.index.names=['班级','姓名']
df_student
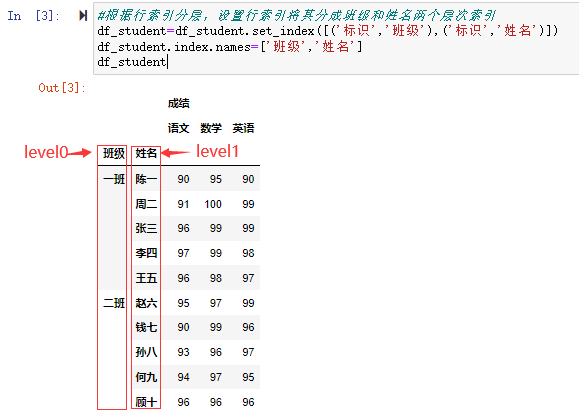
可以看到将数据集的班级和姓名列分成了两个行的层级索引。没有用默认的0-9的行索引
二、数据堆叠与拆堆
层次化索引为DataFrame数据的重排任务提供了一种具有良好一致性的方式,有许多用于重新排列表格数据的基础运算。这些函数也称作重塑(reshape)或轴向旋转(pivot)运算。 常见的数据重塑包括数据的堆叠 stack 和 取消堆叠 unstck
1、数据堆叠 stack
堆叠 stack ,顾名思义,就是将列的数据堆叠形成行。
借用pandas官网的示意图:
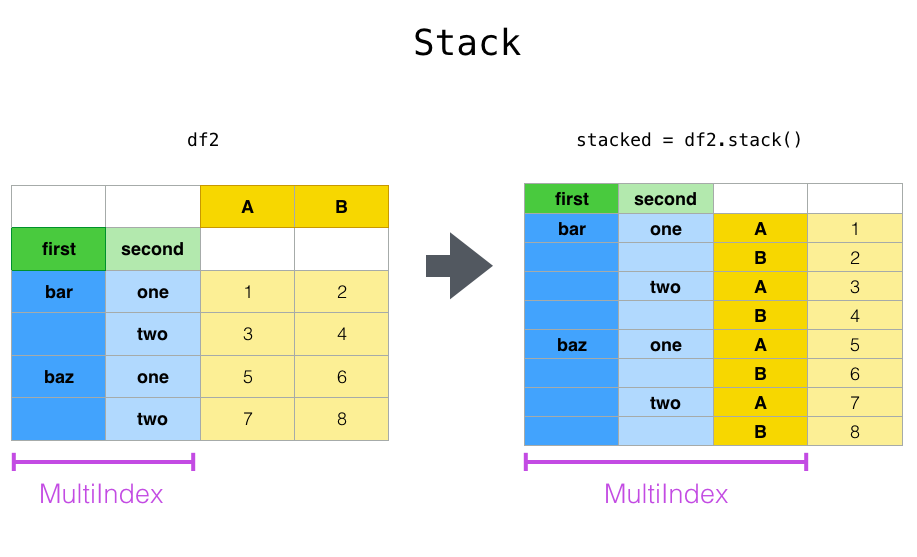
看实际数据数据会更容易理解,为了方便我们取student数据集的前5行记录来进行数据堆叠stack()
df_student[:5]
#将数据进行堆叠
#将数据进行堆叠
df_student5=df_student[:5].stack()
df_student5
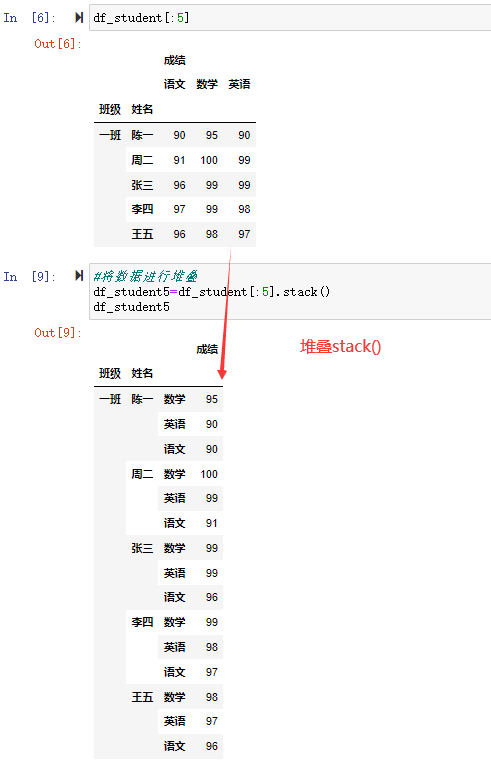
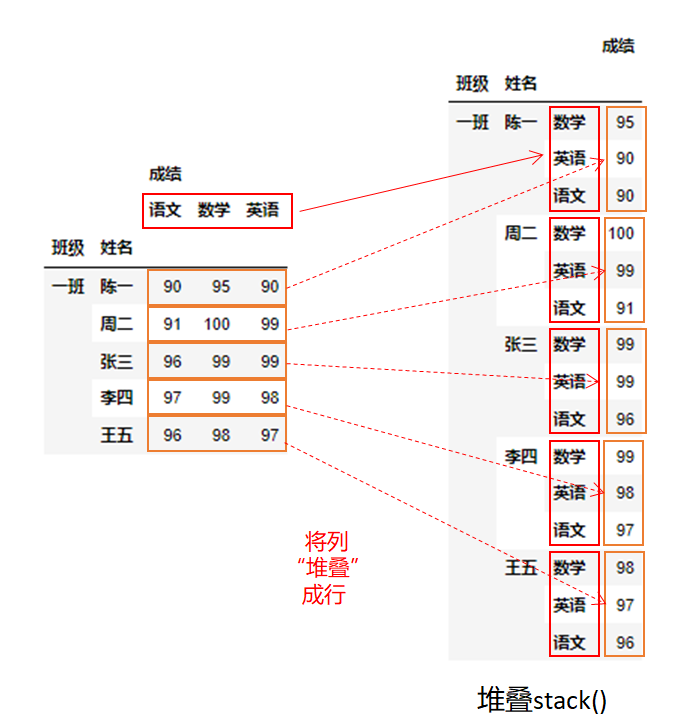
在这里可以看到通过stack()将“语文”、“数学”、"英语",三列,一个个堆叠形成一条记录的三行。这样列数减少了,行数增多了。
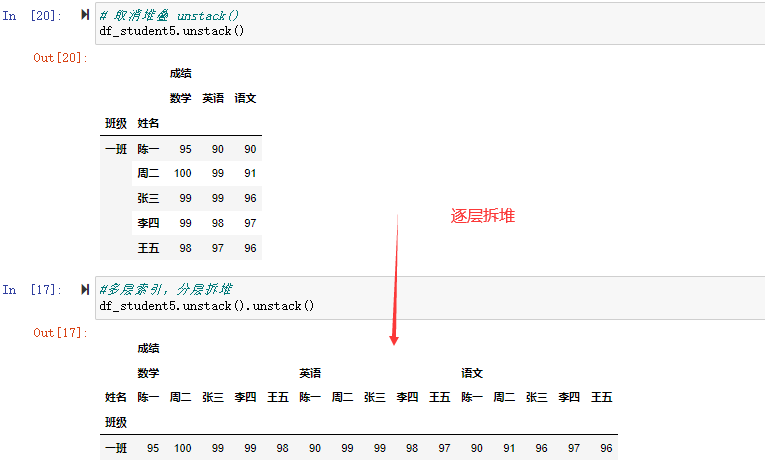
对于多层索引,可以根据指定堆叠层次,默认是最高层次的堆叠。
我们来看指定堆叠层次,如果stack(0),表示堆叠level0层的。
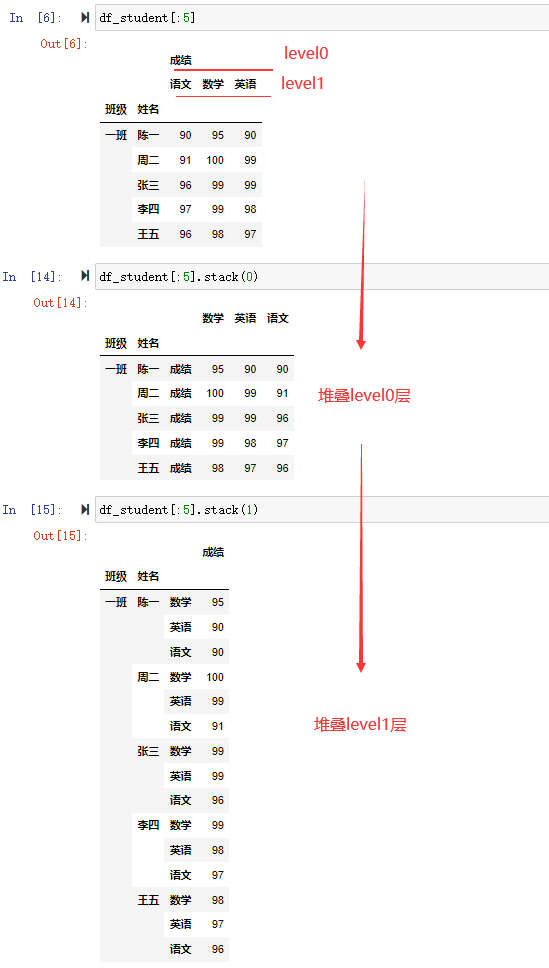
2、取消堆叠 unstack
取消堆叠 unstack是堆叠的反操作。
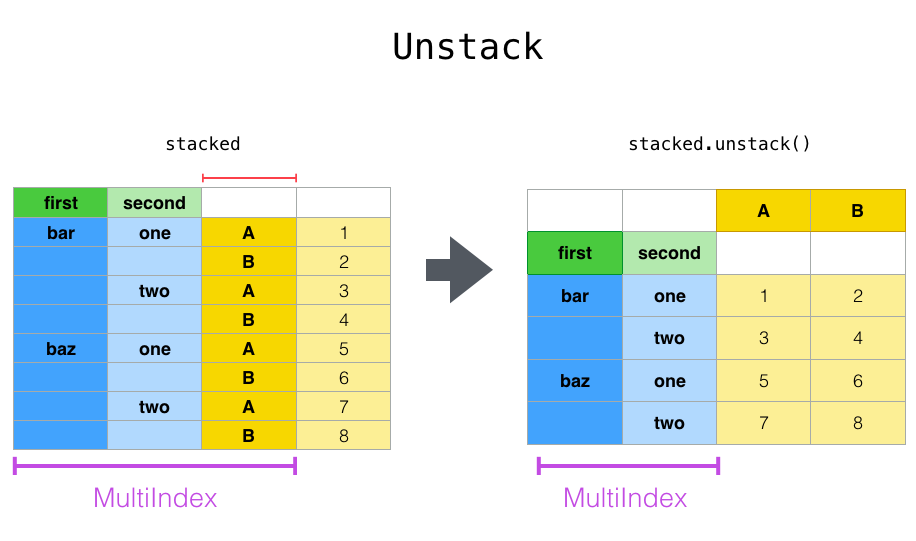
也就是将堆叠好了的行数据,一个个卸下来形成列。这样一来行数减少了,但是列数增多了。
# 取消堆叠 unstack()
df_student5.unstack()
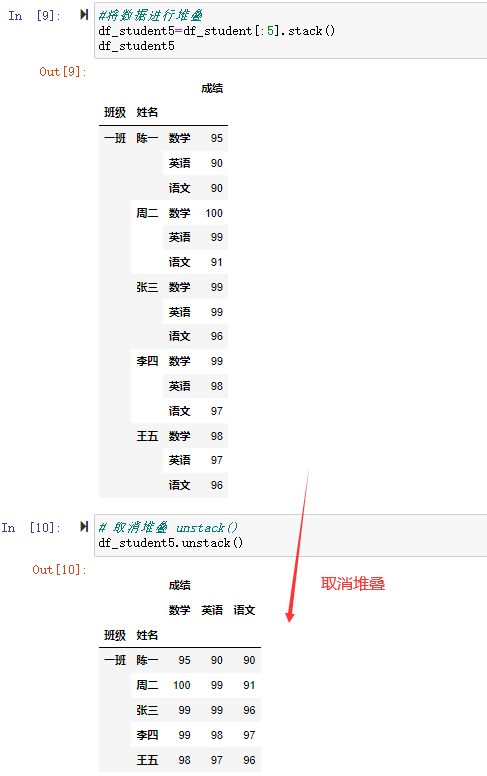
可以看到原来的“语文”、“数学”、"英语"三行,通过unstack()进行拆堆,拆成了三列,明显数据没有那么高了,行数少了,列数多了。
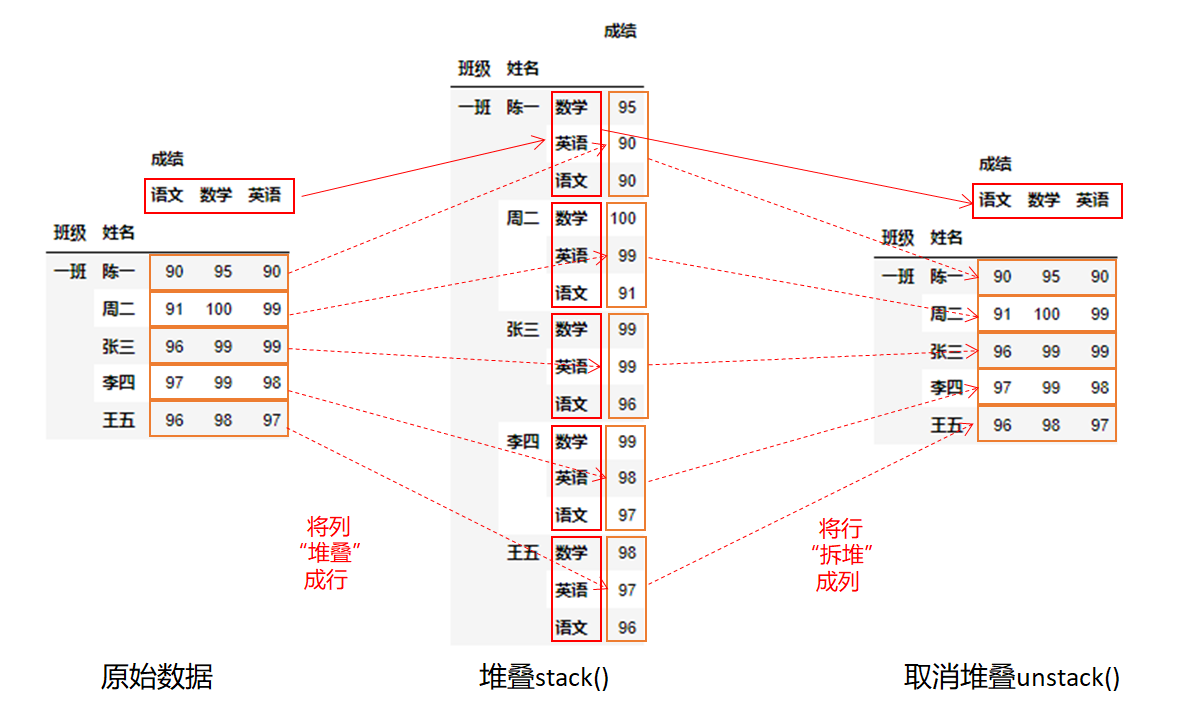
同样对于多层索引可以逐层拆堆
三、数据融合与透视
数据透视是最常用的数据汇总工具,它可以根据一个或者多个指定的维度来聚合数据。实际上搞懂了stack和unstack就很容易搞懂pivot和melt了,stack和unstack根据索引来进行堆叠和拆堆,pivot和melt可以根据指定的数据来进行变换操作灵活性更高。
1、数据融合 melt
来看pandas官网的示意图,是不是和stack的图有点类似,都是将列转换成行,不同的是melt可以指定哪些列固定,哪些列转换成行等灵活性更高。简单说就是将指定的列放到铺开放到行上名为variable(可指定)列,值在value(可指定)列
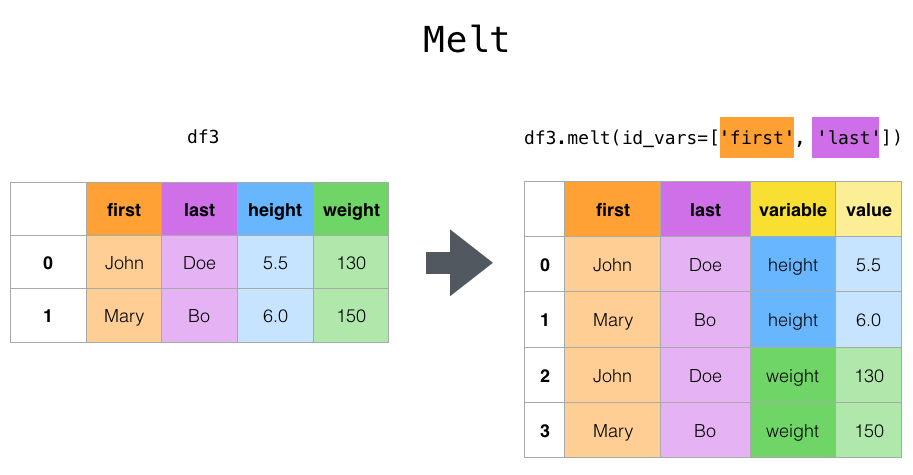 melt语法:
melt语法:
pd.melt(frame: pandas.core.frame.DataFrame,
id_vars=None, value_vars=None,
var_name='variable', value_name='value',
col_level=None)
其中:
- id_varstuple,list或ndarray(可选),用作标识变量的列。
- value_varstuple,列表或ndarray,可选,要取消透视的列。 如果未指定,则使用未设置为id_vars的所有列。
- var_namescalar,用于“变量”列的名称。 如果为None,则使用frame.columns.name或“variable”。
- value_namescalar,默认为“ value”,用于“ value”列的名称。
- col_levelint或str,可选,如果列是MultiIndex,则使用此级别来融化。
我们还是来看示例: 数据集还是student数据集,为了演示方便取前5条记录
df_student=df[['班级','2-姓名','4-语文','5-数学','6-英语']]
df_student.columns=[['标识','标识','成绩','成绩','成绩'],['班级','姓名','语文','数学','英语']]
df_student[0:5]

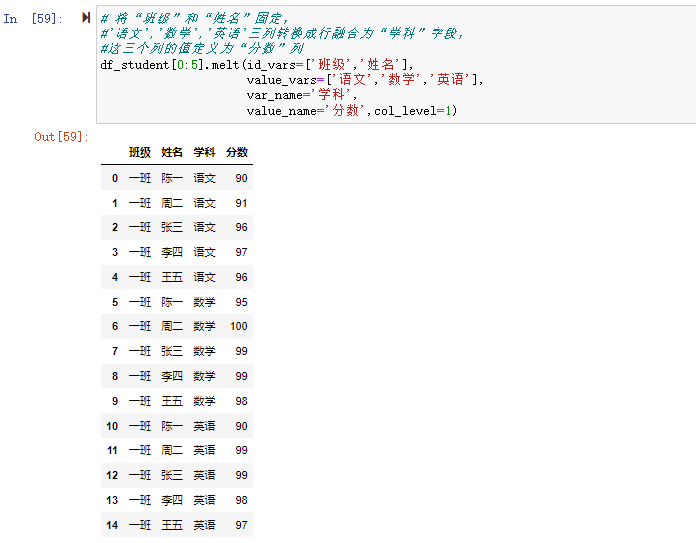
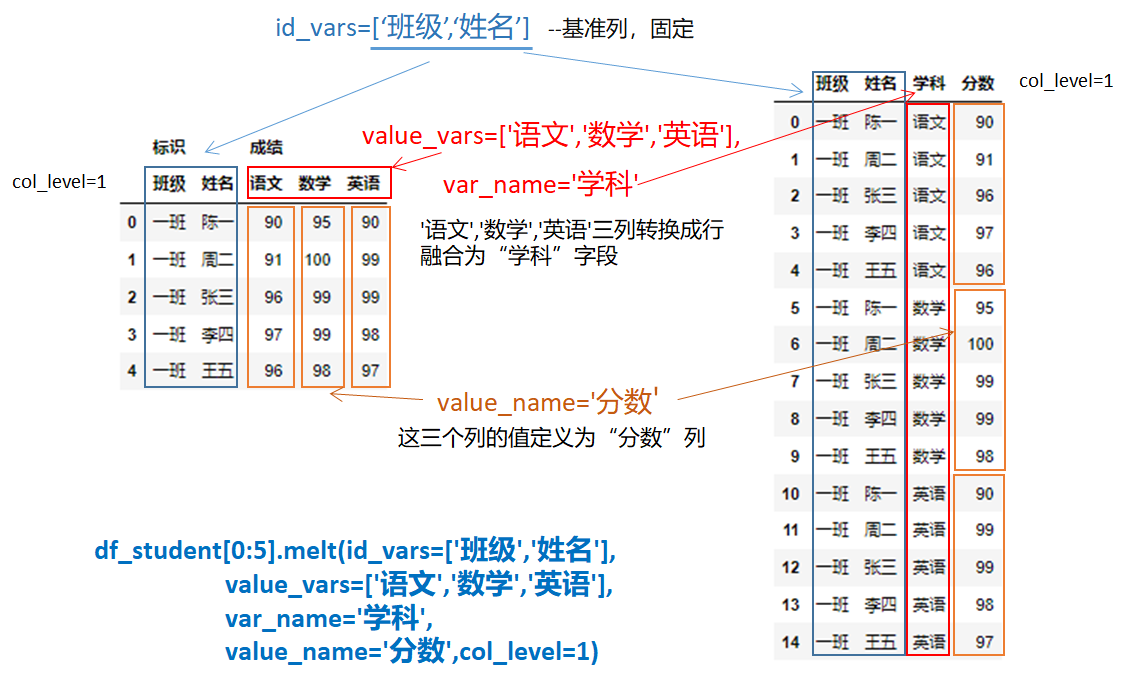
现在将“班级”和“姓名”固定,'语文','数学','英语'三列转换成行融合为“学科”字段,这三个列的值定义为“分数”列。
# 将“班级”和“姓名”固定,'语文','数学','英语'三列转换成行融合为“学科”字段,这三个列的值定义为“分数”列
df_student[0:5].melt(id_vars=['班级','姓名'],
value_vars=['语文','数学','英语'],
var_name='学科',
value_name='分数',col_level=1)
 具体实现如下图所示:
具体实现如下图所示:
2、数据透视 pivot
来看pandas官网的示意图,是不是和unstack的图有点类似,将行数据转换成列。同样pivot提供了更多的参数可以指定相应的数据进行转换,比unstack更加灵活。
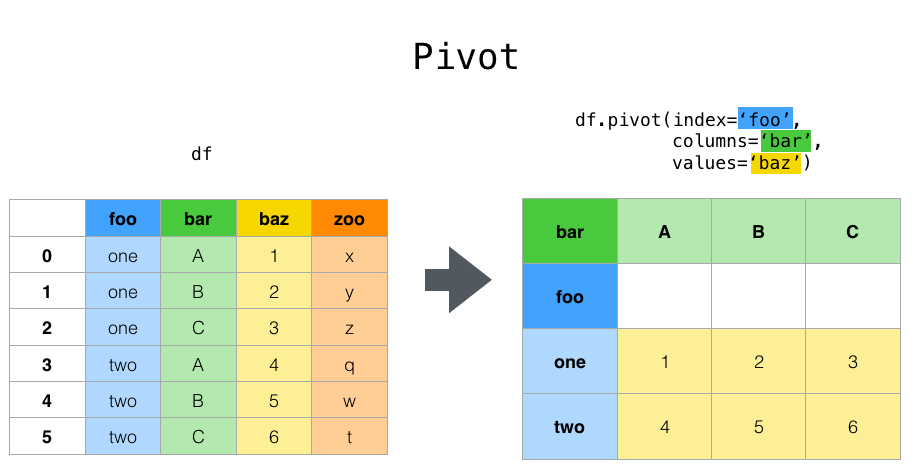
这里有三个参数,作用分别是:
- index:新 df 的索引列,用于分组,如果为None,则使用现有索引
- columns:新 df 的列,如果透视后有重复值会报错
- values:用于填充 df 的列。 如果未指定,将使用所有剩余的列,并且结果将具有按层次结构索引的列
df_student5=df_student[0:5].melt(id_vars=['班级','姓名'],
value_vars=['语文','数学','英语'],
var_name='学科',
value_name='分数',col_level=1)
df_student5
df_student5.pivot(index=['班级','姓名'],columns='学科',values='分数')
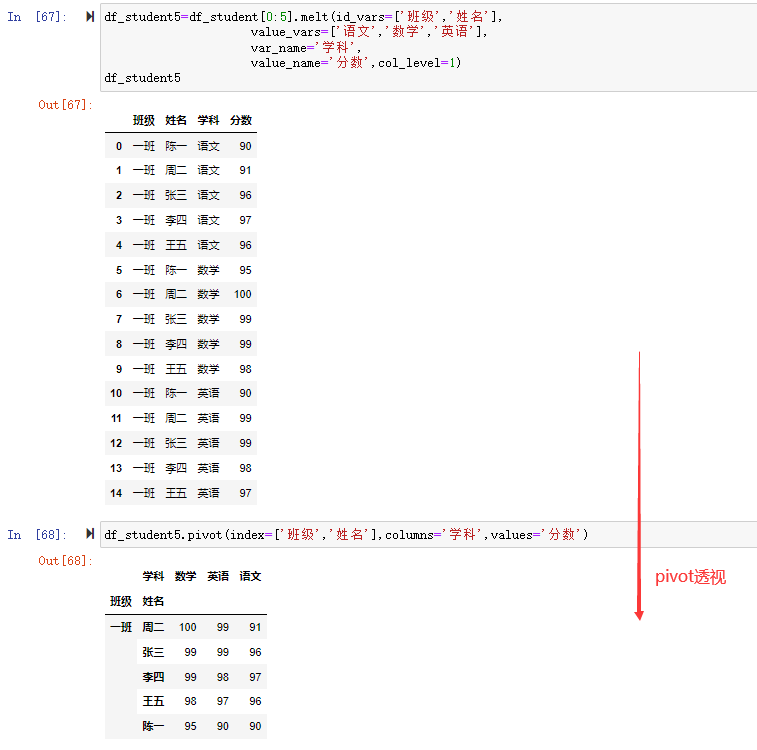
这里通过pivot将“学科”的行数据透视转换成“数学”、“英语”、“语文”三列,具体实现如下图所示:
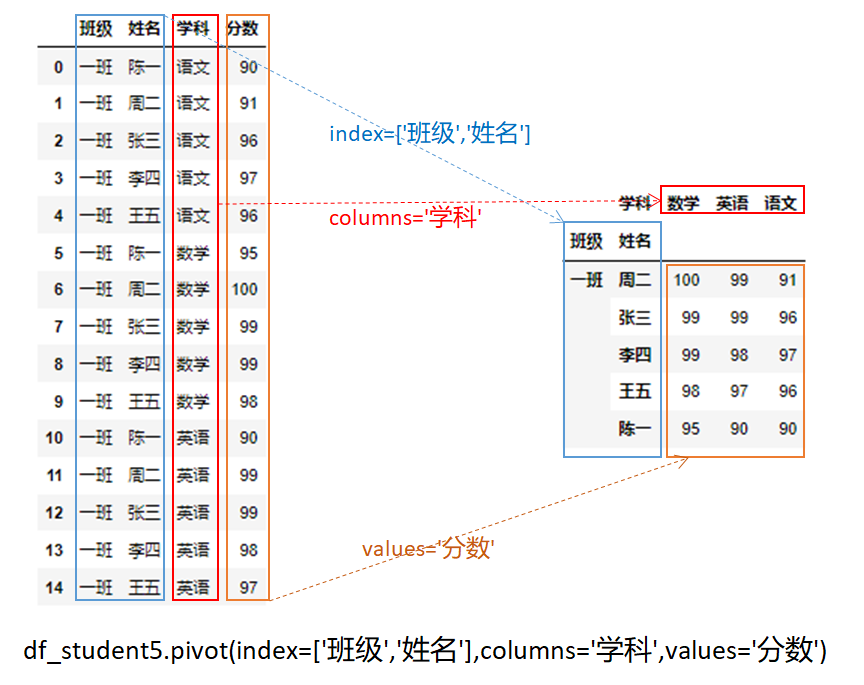 可以看出privot实际和unstack类似是由行转换成列的视图,但比起unstack更加灵活。
可以看出privot实际和unstack类似是由行转换成列的视图,但比起unstack更加灵活。
至此,介绍了pandas的多层索引及pandas的4种重塑操作:stack、unstack、pivot、melt: stack、unstack是基础:stack实现列转行,unstack实现行转列。 melt与stack类似,比stack更加灵活。 pivot与unstack类似,比unstack更加灵活。
数据集及源代码见:https://github.com/xiejava1018/pandastest.git
作者博客:http://xiejava.ishareread.com/

关注:微信公众号,一起学习成长!