
一图胜千言,将信息可视化(绘图)是数据分析中最重要的工作之一。它除了让人们对数据更加直观以外,还可以帮助我们找出异常值、必要的数据转换、得出有关模型的想法等等。pandas 在数据分析、数据可视化方面有着较为广泛的应用。本文将通过实例介绍pandas的数据绘图。
pandas的数据可视化依赖于matplotlib模块的pyplot类,matplotlib在安装Pandas会自动安装。Matplotlib可以对图形做细节控制,绘制出出版质量级别的图形,通过Matplotlib,可以简单地绘制出常用的统计图形。pandas 对 Matplotlib 绘图软件包的基础上单独封装了一个plot()接口,通过调用该接口可以实现常用的绘图操作。 让我们先来认识mataplotlib图形的基本构成。
一、matplotlib图形基本构成
import matplotlib.pyplot as plt
import numpy as np
data=np.arange(10)
plt.plot(data)
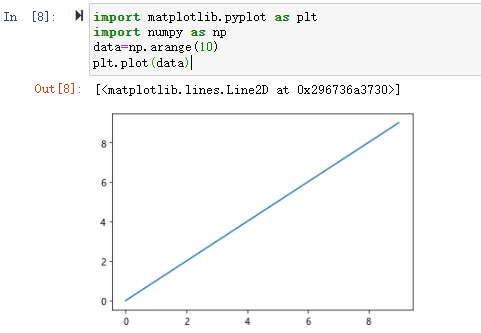
通过引入matplotlib模块的pyplot类,将数据传入plot()的接口,就可以将数据以图形化的方式展示出来。Matplotlib 生成的图形主要由以下几个部分构成:
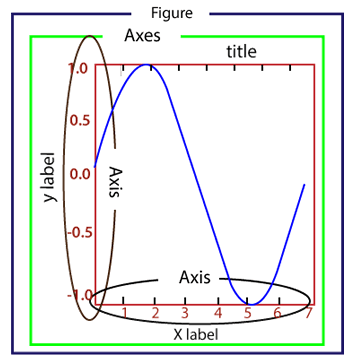
- Figure:指整个图形,您可以把它理解成一张画布,它包括了所有的元素,比如标题、轴线等;
- Axes:绘制 2D图像的实际区域,也称为轴域区,或者绘图区;
- Axis:指坐标系中的垂直轴与水平轴,包含轴的长度大小(图中轴长为 7)、轴标签(指 x轴,y轴)和刻度标签;
- Artist:在画布上看到的所有元素都属于 Artist对象,比如文本对象(title、xlabel、ylabel)、Line2D 对象(用于绘制2D图像)等。
了解matplotlib图形的基本构成非常重要,绘图就是通过matplotlib提供的方法来定义和设置这些基本图形的构成元素来将数据显示在这些元素中。
二、matplotlib显示中文
Matplotlib 默认不支持中文字体,这因为 Matplotlib 只支持 ASCII 字符,但中文标注更加符合中国人的阅读习惯。下面介绍如何在 Windows 环境下让 Matplotlib 显示中文。
1、方法一:临时重写配置文件(临时)
通过临时重写配置文件的方法,可以解决 Matplotlib 显示中文乱码的问题,代码如下所示:
import matplotlib.pyplot as plt
plt.rcParams["font.sans-serif"]=["SimHei"] #设置字体
plt.rcParams["axes.unicode_minus"]=False #该语句解决图像中的“-”负号的乱码问题
2、方法二:修改配置文件 (永久)
通过直接修改配置文件的方法,可以一劳永逸的解决 Matplotlib 的中文乱码问题。注意此过程在 Windows 环境下进行。 Matplotlib 从配置文件 matplotlibrc 中读取相关配置信息,比如字体、样式等,因此我们需要对该配置文件进行更改。使用如下代码查看 matplotlibrc 所在的目录:
import matplotlib
matplotlib.matplotlib_fname()

打开配置文件后,找到以下信息:
font.family: sans-serif
font.serif: DejaVu Serif, Bitstream Vera Serif, Computer Modern Roman, New Century Schoolbook, Century Schoolbook L, Utopia, ITC Bookman, Bookman, Nimbus Roman No9 L, Times New Roman, Times, Palatino, Charter, serif
修改配置将#注释去掉,并将微软雅黑Microsoft YaHei的字体给加上。
 最后,在windows的字体目录中复制中文字体微软雅黑:
C:\Windows\Fonts\Microsoft YaHei UI
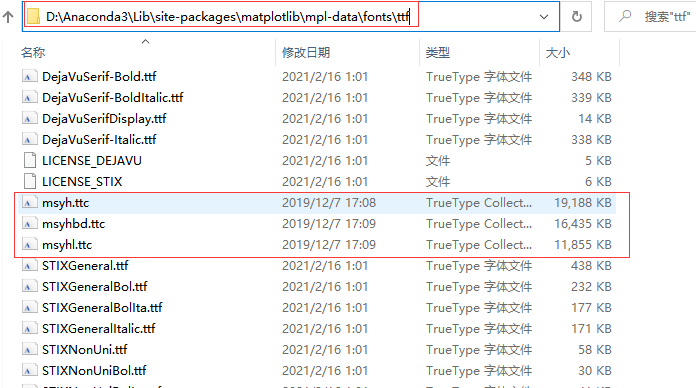
将微软雅黑的字体复制粘贴到matplotlib的字体库中,字体库路径就在matplotlibrc 所在的目录下
D:\Anaconda3\Lib\site-packages\matplotlib\mpl-data\fonts\ttf
最后,在windows的字体目录中复制中文字体微软雅黑:
C:\Windows\Fonts\Microsoft YaHei UI
将微软雅黑的字体复制粘贴到matplotlib的字体库中,字体库路径就在matplotlibrc 所在的目录下
D:\Anaconda3\Lib\site-packages\matplotlib\mpl-data\fonts\ttf
 如果是jupyter notbook重启启动jupyter notbook让它重新读取配置文件即可。
如果是jupyter notbook重启启动jupyter notbook让它重新读取配置文件即可。
三、pandas绘图
数据分析将数据进行可视化绘图展示离不开数据,pandas的两大数据结构Series和DataFrame都提供了相应的方法很方便的进行数据的可视化绘图展示。
1、数据
pandas 提供了 plot() 方法可以快速方便地将 Series 和 DataFrame 中的数据进行可视化。
a) Series
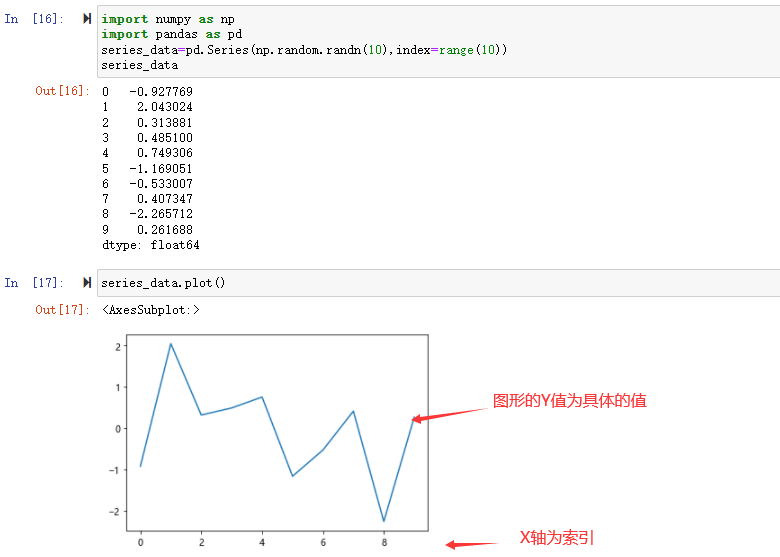
Series 使用 plot 时 x 轴为索引,y 轴为索引对应的具体值:
import numpy as np
import pandas as pd
series_data=pd.Series(np.random.randn(10),index=range(10))
series_data
series_data.plot()
b) DataFrame
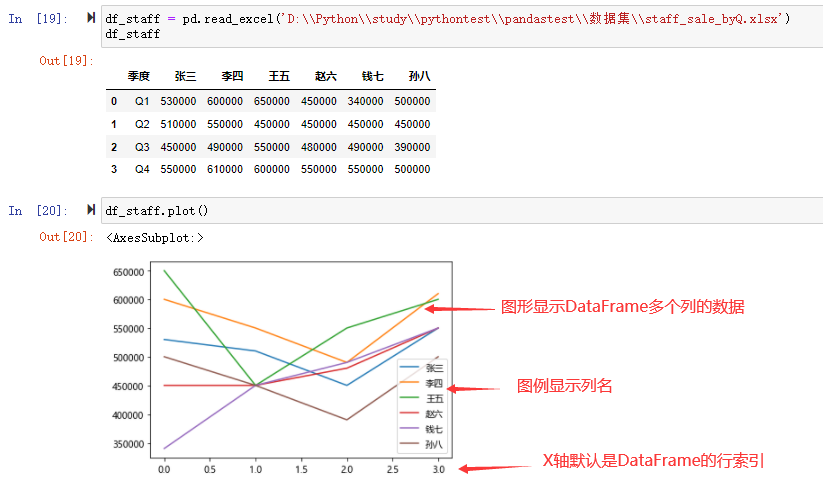
DataFrame 使用 plot 时 x 轴为索引,y 轴为索引对应的多个具体值:
df_staff = pd.read_excel('D:\\Python\\study\\pythontest\\pandastest\\数据集\\staff_sale_byQ.xlsx')
df_staff
df_staff.plot()
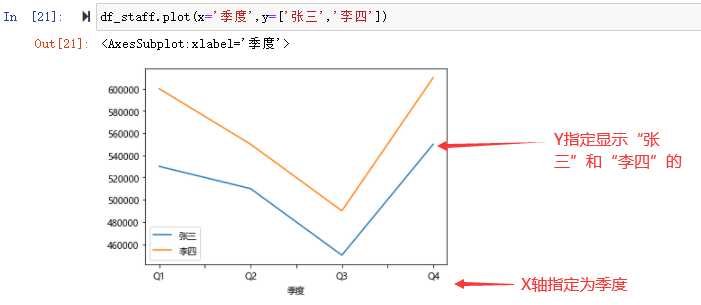
 plot()可以通过传入x和y指定显示具体的列数据
plot()可以通过传入x和y指定显示具体的列数据
#指定X轴及y显示的列数据
df_staff.plot(x='季度',y=['张三','李四'])
2、图形
plot 默认为折线图,折线图也是最常用和最基础的可视化图形,足以满足我们日常 80% 的需求。 除了使用默认的线条绘图外,还可以使用其他绘图方式,如下所示:
- 柱状图:bar() 或 barh()
- 箱形图:box()
- 区域图:area()
- 饼状图:pie()
- 散点图:scatter()
- 直方图:hist()
a) 柱状图
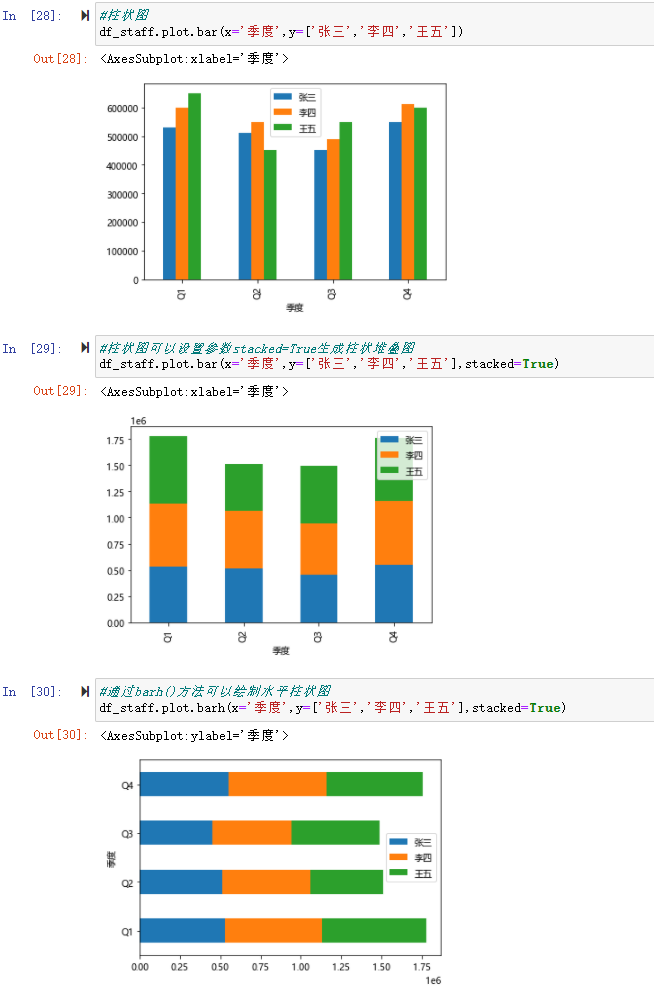
柱状图(bar chart),使用与轴垂直的柱子,通过柱形的高低来表达数据的多少,适用于数据的对比,在整体中也能看到数据的发展变化趋势。 DataFrame 可以直接调用 plot.bar() 生成折线图,与折线图类似,x 轴为索引,其他数字类型的列为 y 轴上的条形,可以设置参数stacked=True生成柱状堆叠图 df.plot.bar() df.plot.barh() # 横向 df[:5].plot.bar(x='name', y='Q4') # 指定xy轴 df[:5].plot.bar('name', ['Q1', 'Q2']) # 指定xy轴
#柱状图
df_staff.plot.bar(x='季度',y=['张三','李四','王五'])
#柱状图可以设置参数stacked=True生成柱状堆叠图
df_staff.plot.bar(x='季度',y=['张三','李四','王五'],stacked=True)
#通过barh()方法可以绘制水平柱状图
df_staff.plot.barh(x='季度',y=['张三','李四','王五'],stacked=True)
b) 箱形图
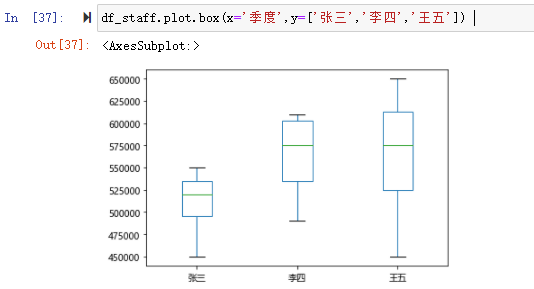
箱形图(Box Chart)又称盒须图、盒式图或箱线图,是一种用作显示一组数据分布情况的统计图。Series.plot.box() 、 DataFrame.plot.box(), 和 DataFrame.boxplot() 都可以绘制箱形图。 从箱形图中我们可以观察到:
- 一组数据的关键值:中位数、最大值、最小值等。
- 数据集中是否存在异常值,以及异常值的具体数值。
- 数据是否是对称的。
- 这组数据的分布是否密集、集中。
- 数据是否扭曲,即是否有偏向性。
df_staff.plot.box(x='季度',y=['张三','李四','王五'])
c) 区域图
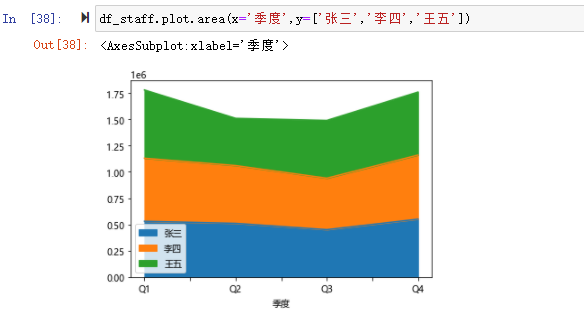
区域图(Area Chart),又叫面积图。 将折线图中折线与自变量坐标轴之间的区域使用颜色或者纹理填充,这样一个填充区域叫做面积,颜色的填充可以更好的突出趋势信息,需要注意的是颜色要带有一定的透明度,透明度可以很好的帮助使用者观察不同序列之间的重叠关系,没有透明度的面积会导致不同序列之间相互遮盖减少可以被观察到的信息。 面积图默认情况下是堆叠的。 要生成堆积面积图,每列必须全部为正值或全部为负值。
df_staff.plot.area(x='季度',y=['张三','李四','王五'])
d) 饼状图
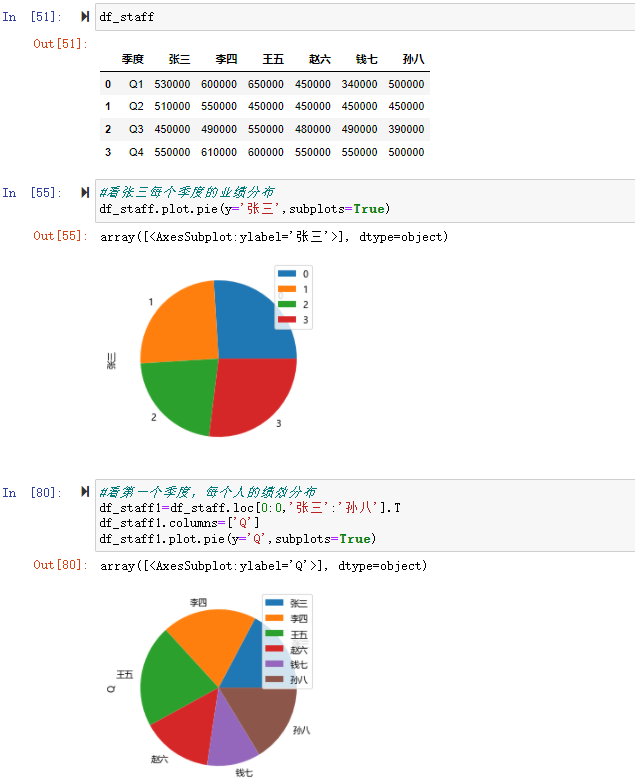
饼图(Pie Chart)广泛得应用在各个领域,用于表示不同分类的占比情况,通过弧度大小来对比各种分类。饼图通过将一个圆饼按照分类的占比划分成多个区块,整个圆饼代表数据的总量,每个区块(圆弧)表示该分类占总体的比例大小,所有区块(圆弧)的加和等于 100%。 可以使用 DataFrame.plot.pie() 或 Series.plot.pie() 创建饼图
df_staff
#看张三每个季度的业绩分布
df_staff.plot.pie(y='张三',subplots=True)
#看第一个季度,每个人的绩效分布
df_staff1=df_staff.loc[0:0,'张三':'孙八'].T
df_staff1.columns=['Q']
df_staff1.plot.pie(y='Q',subplots=True)
e) 散点图
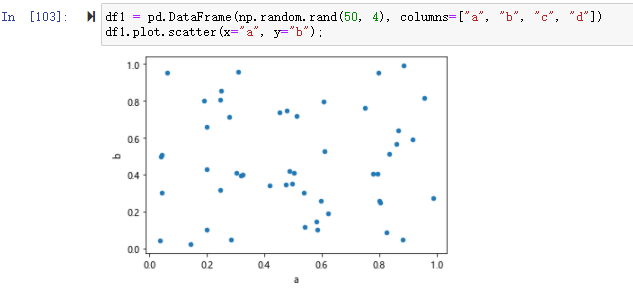
散点图(Scatter graph)也叫 X-Y 图,它将所有的数据以点的形式展现在直角坐标系上,以显示变量之间的相互影响程度,点的位置由变量的数值决定。 通过观察散点图上数据点的分布情况,我们可以推断出变量间的相关性。如果变量之间不存在相互关系,那么在散点图上就会表现为随机分布的离散的点,如果存在某种相关性,那么大部分的数据点就会相对密集并以某种趋势呈现。
df1 = pd.DataFrame(np.random.rand(50, 4), columns=["a", "b", "c", "d"])
df1.plot.scatter(x="a", y="b");
f) 直方图
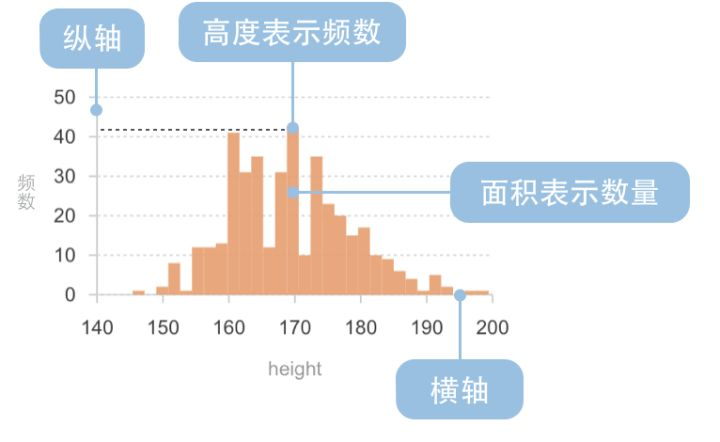
直方图(Histogram),又称质量分布图,是一种统计报告图,它是根据具体数据的分布情况,画成以组距为底边、以频数为高度的一系列连接起来的直方型矩形图。
#构建数据集
df4=pd.DataFrame({
"a": np.random.randn(1000) + 1,
"b": np.random.randn(1000),
"c": np.random.randn(1000) - 1,
"d": np.random.randn(1000) - 2,
},columns=['a','b','c','d'])
df4
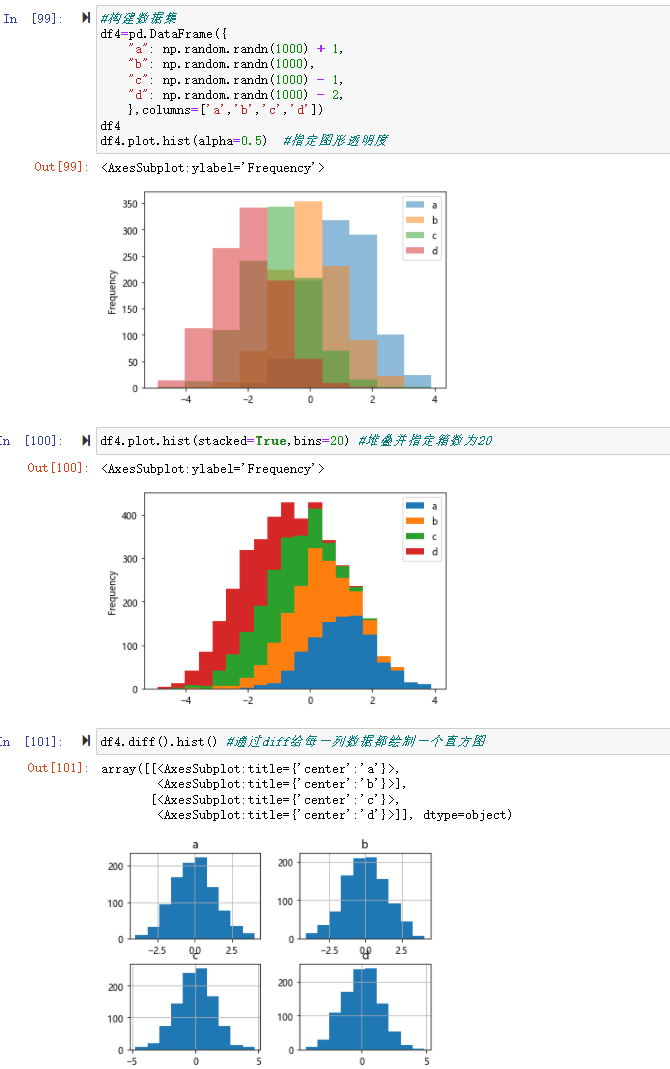
df4.plot.hist(alpha=0.5) #指定图形透明度
df4.plot.hist(stacked=True,bins=20) #堆叠并指定箱数为20
df4.diff().hist() #通过diff给每一列数据都绘制一个直方图
至此,本文介绍了pandas常用的绘图组件matplotlib,包括mataplotlib绘图的基本构成,如何在windows下解决中文问题,并通过实例介绍了如何通过pandas的数据集绘制折线图、箱线图、柱状图、饼图、面积图、散点图、直方图等。
参考资料:《利用python进行数据分析》、pandas官网 user guide
数据集及源代码见:https://github.com/xiejava1018/pandastest.git
作者博客:http://xiejava.ishareread.com/

关注:微信公众号,一起学习成长!