
在应用机器学习的过程中,很大一部分工作都是在做数据的处理,一个非常常见的场景就是将一个list序列的特征数据拆成多个单独的特征数据。
比如数据集如下所示:
data = [['John', '25', 'Male',[99,100,98]],
['Emily', '22', 'Female',[97,99,98]],
['Michael', '30', 'Male',[97,99,100]]]
df_data= pd.DataFrame(data,columns=['Name', 'Age', 'Gender','Score'])
df_data
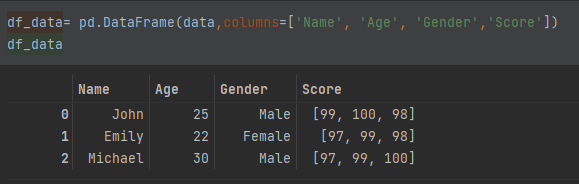
很多场景是需要将类似于Score的list序列特征,拆成多个特征值如这里的语、数、外的分数。
下面通过几个实例来将dataframe列中的list序列转换为多列。
1、一维序列拆成多列
可以通过在列上应用Series来进行拆分。
df_score=df_data['Score'].apply(pd.Series).rename(columns={0:'English',1:'Math',2:'Chinese'})
df_score
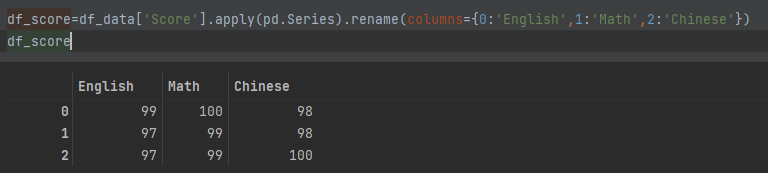
可以看到将Score的数组,拆分成了English、Math、Chinese三个特征字段了
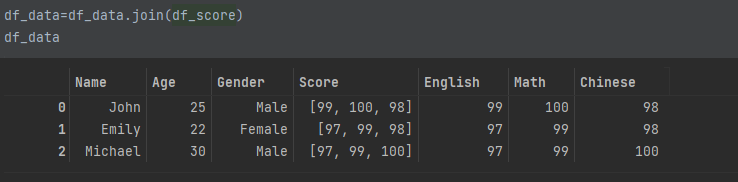
df_data=df_data.join(df_score)
df_data
2、二维序列拆成多列
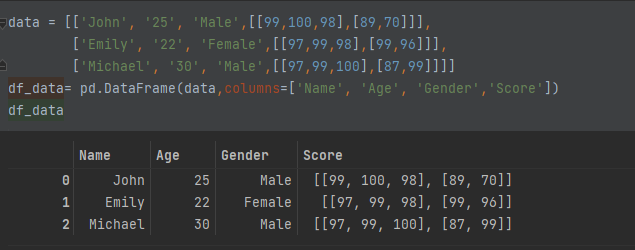
用同样的思路也可以将二维序列的特征列拆成多列 如特征列是二维序列,序列里还有多个序列
data = [['John', '25', 'Male',[[99,100,98],[89,70]]],
['Emily', '22', 'Female',[[97,99,98],[99,96]]],
['Michael', '30', 'Male',[[97,99,100],[87,99]]]]
df_data= pd.DataFrame(data,columns=['Name', 'Age', 'Gender','Score'])
df_data
df_score=df_data['Score'].apply(pd.Series)
df_score_1=df_score[0].apply(pd.Series).rename(columns={0:'English',1:'Math',2:'Chinese'})
df_score_2=df_score[1].apply(pd.Series).rename(columns={0:'Biology',1:'Geography'})
df_score=df_score_1.join(df_score_2)
df_data=df_data.join(df_score_1).join(df_score_2)
df_data

另外一种情况就是序列里面只有一个序列的二维序列,数据如下所示:
data = [['John', '25', 'Male',[[99,100,98,89,70]]],
['Emily', '22', 'Female',[[97,99,98,99,96]]],
['Michael', '30', 'Male',[[97,99,100,87,99]]]]
df_data= pd.DataFrame(data,columns=['Name', 'Age', 'Gender','Score'])
df_data
这样也可以通过多次应用Series来进行拆分,也可以先explode()再应用Series来进行拆分。
df_score=df_data['Score'].apply(pd.Series)[0].apply(pd.Series).rename(columns={0:'English',1:'Math',2:'Chinese',3:'Biology',4:'Geography'})
df_score

df_score=df_data['Score'].explode().apply(pd.Series).rename(columns={0:'English',1:'Math',2:'Chinese',3:'Biology',4:'Geography'})
df_score

两者效果是一样的。
博客地址:http://xiejava.ishareread.com/

关注:微信公众号,一起学习成长!