
做数据分析很大一部分工作量都是在对数据处理,因为数据来源的质量问题,不能保证所有的数据都是正常的。对于数据分析和处理来说pandas无疑是常用的利器。下面通过一个实例来用pandas对波形异常数据进行实战处理。
读取数据
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df_data=pd.read_csv('data\HRTrend测试波形.csv')
df_data
从csv导入的数据是文本字符串类型的,用《Python将列表中的数据写入csv并正确读取解析》中介绍的方法将文本数据转成列表。
def str2list(str):
return np.fromstring(str[1:-1], sep=' ')
df_data['HRTrend']=df_data['HRTrend'].apply(str2list)
df_data
 用plt查看图形
用plt查看图形
fig,axes = plt.subplots(3,4,figsize=(12,4))
i=0
for x in range(3):
for y in range(4):
axes[x,y].plot(df_data['HRTrend'][i])
i=i+1
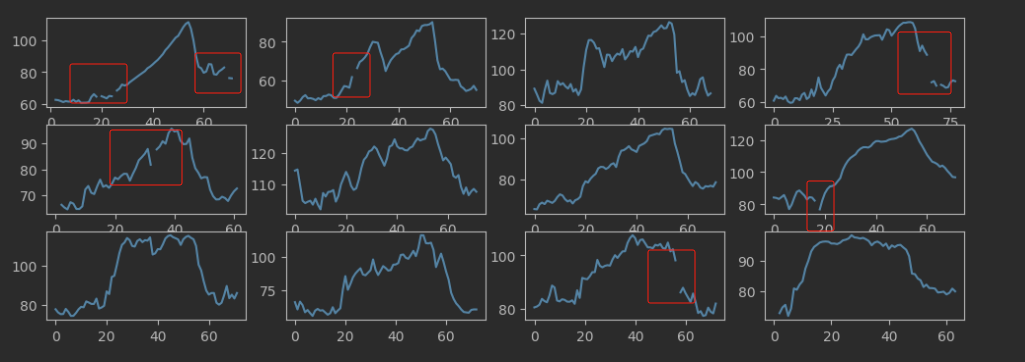
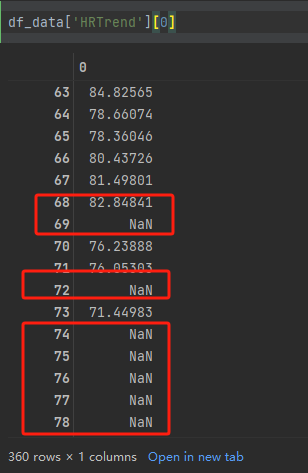
从图形上看出现了异常。我们抽一个数据进行查看,发现前后有很多空值,并且在数据中也存在缺失值。
df_data['HRTrend'][0]
plt.plot(df_data['HRTrend'][0])
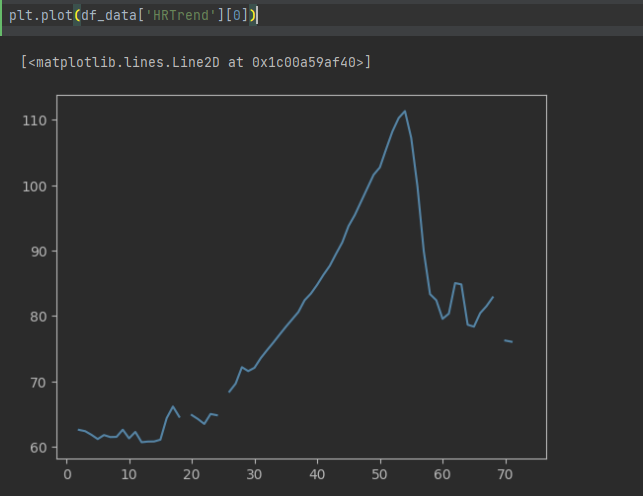
用plt画出图形,可以看到因为有缺失值所以图形并不连续。
异常数据处理
为了更好的展示图像,为以后的数据分析准备数据,我们需要将前后的空值去掉,对于中间存在的异常值我们可以用前值或后值进行填充。
# 定义一个方法,先将空值用0填充,然后去首尾的0,再将中间存在异常的值用前值填充。
def ruledata(df_cloumn):
ps=pd.Series(df_cloumn).fillna(0) #先将为空值用0填充
values=pd.Series(np.trim_zeros(ps)).replace(to_replace=0, method='ffill').values #去首尾0,然后用异常值填充
return values
df_data['rule_HRTrend']=df_data['HRTrend'].apply(ruledata) #将异常数据处理的方法进行应用处理异常值
fig,axes = plt.subplots(3,4,figsize=(12,4))
i=0
for x in range(3):
for y in range(4):
axes[x,y].plot(df_data['rule_HRTrend'][i])
i=i+1
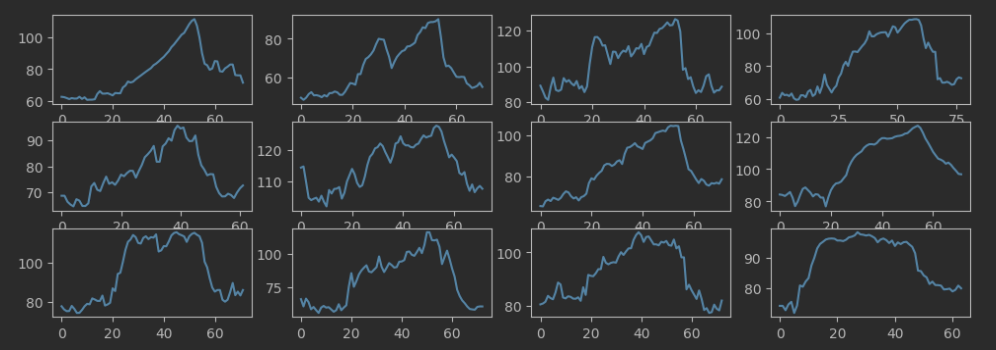
最后可以发现经过异常值修复后图形变得正常连续了。
博客地址:http://xiejava.ishareread.com/

关注:微信公众号,一起学习成长!