

对于APP的数据爬取或需要构建复杂的接口参数数据的爬取可以通过mitmproxy抓包还原流量,解析流量数据包来获取。mitmproxy是一个免费的开源交互式的HTTPS代理工具。它类似于其他抓包工具如WireShark和Fiddler,支持抓取HTTP和HTTPS协议的数据包,并可以通过控制台形式进行操作。mitmproxy具有两个非常有用的组件:mitmdump和mitmweb。mitmdump是mitmproxy的命令行接口,可以直接抓取请求数据。
本文介绍通过通过mitmdump爬取京东金榜数据。
京东金榜只有H5小程序和京东APP才有,用直接http请求来爬取数据很麻烦需要找到相应的接口构建很复杂的参数。通过mitmproxy代理抓包,从流量包中解析需要的数据相对来说要容易得多。
一、准备工作
安装mitmproxy并配置客户端。具体步骤见《mitmproxy安装与配置》 如果需要通过APP爬取,需要安装APP的模拟器,这里推荐用夜神模拟器。 启动模拟器后APP的网络配置一样的要配置通过mitmproxy的代理,因为APP一般都是通过HTTPS访问的,还需要安装证书。
1、模拟器安卓操作系统安装证书
夜神模拟器可以直击访问本地的windows目录和模拟器的安卓目录,我们需要将mitmproxy的安卓证书传输到模拟器的安卓文件夹,点击夜神模拟器的文件助手
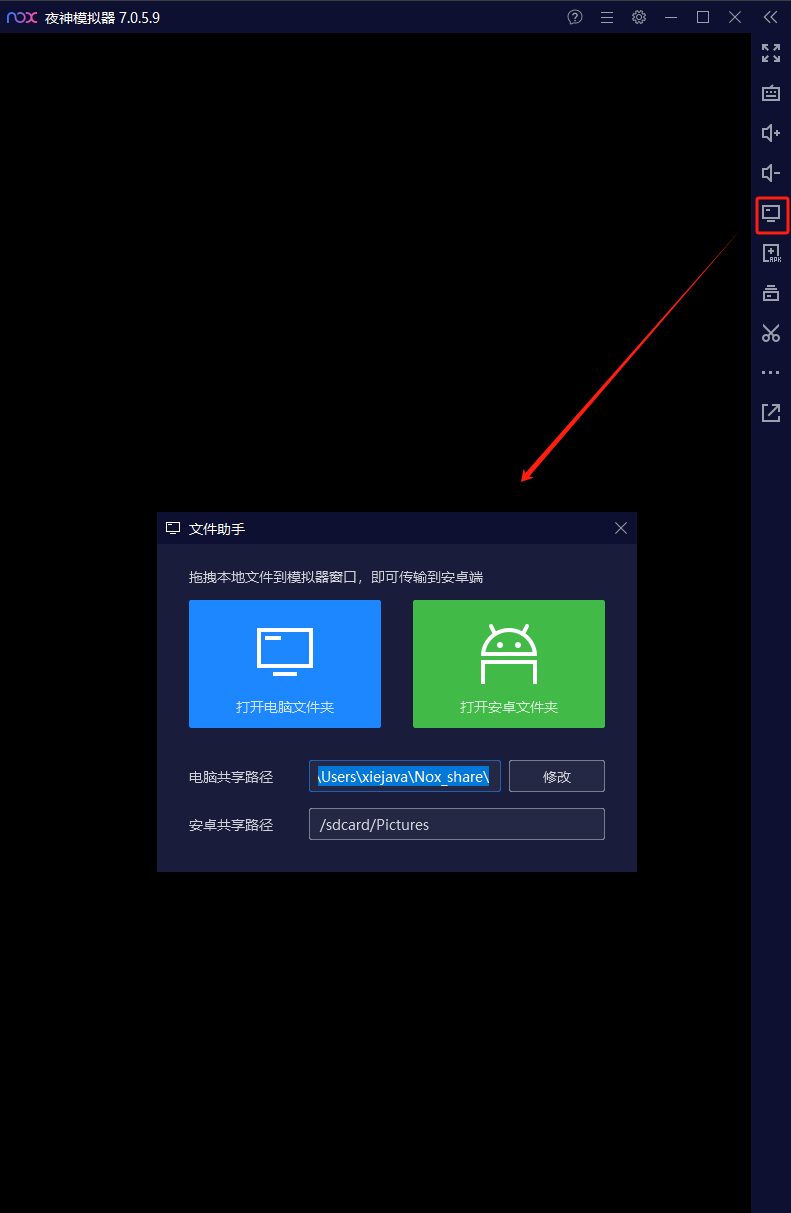
将mitmproxy的安卓证书传到安卓端。
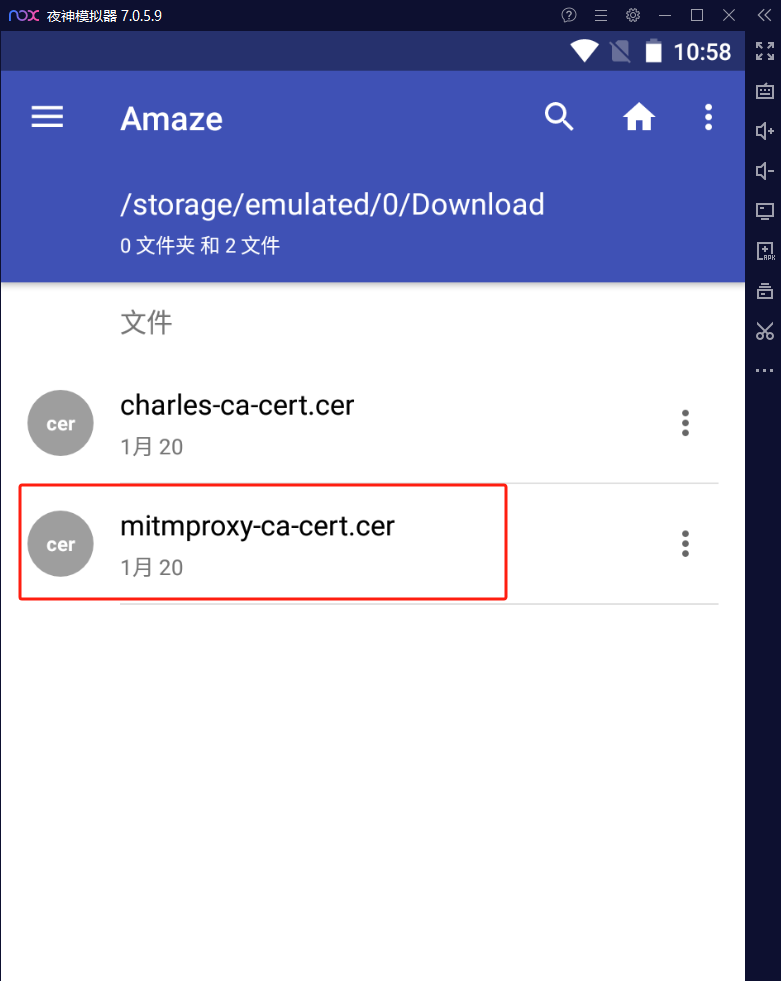
安装证书: 安卓模拟器-->设置-->安全-->从SD卡安装
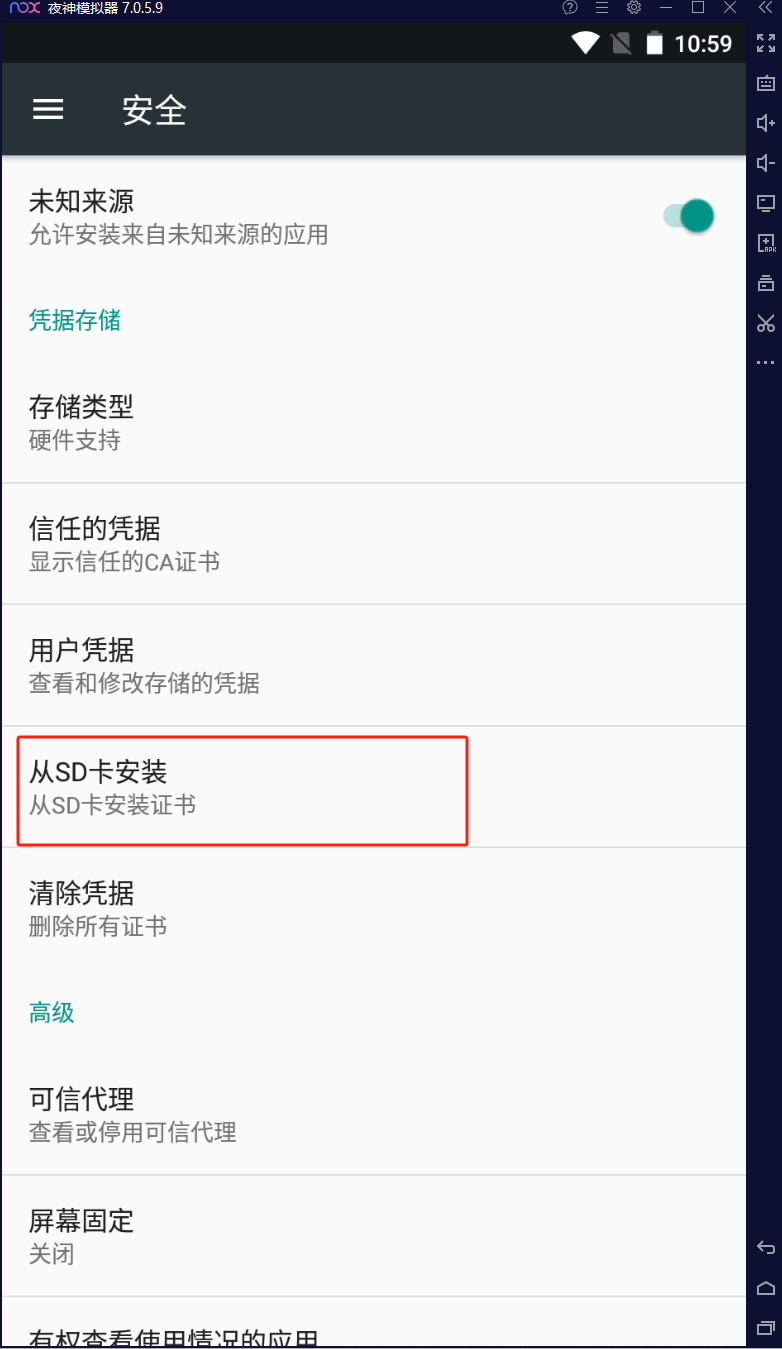
选择开始传到安卓文件夹中的证书文件
输入PIN码
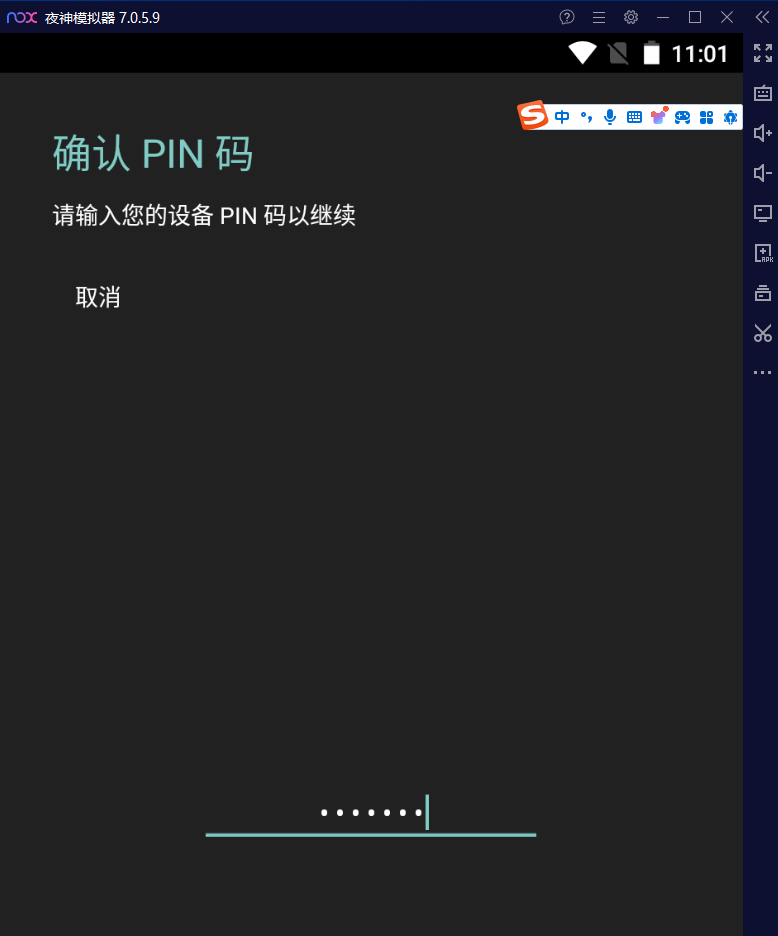
为证书取个名字如mitmproxy,点击确定就可以了
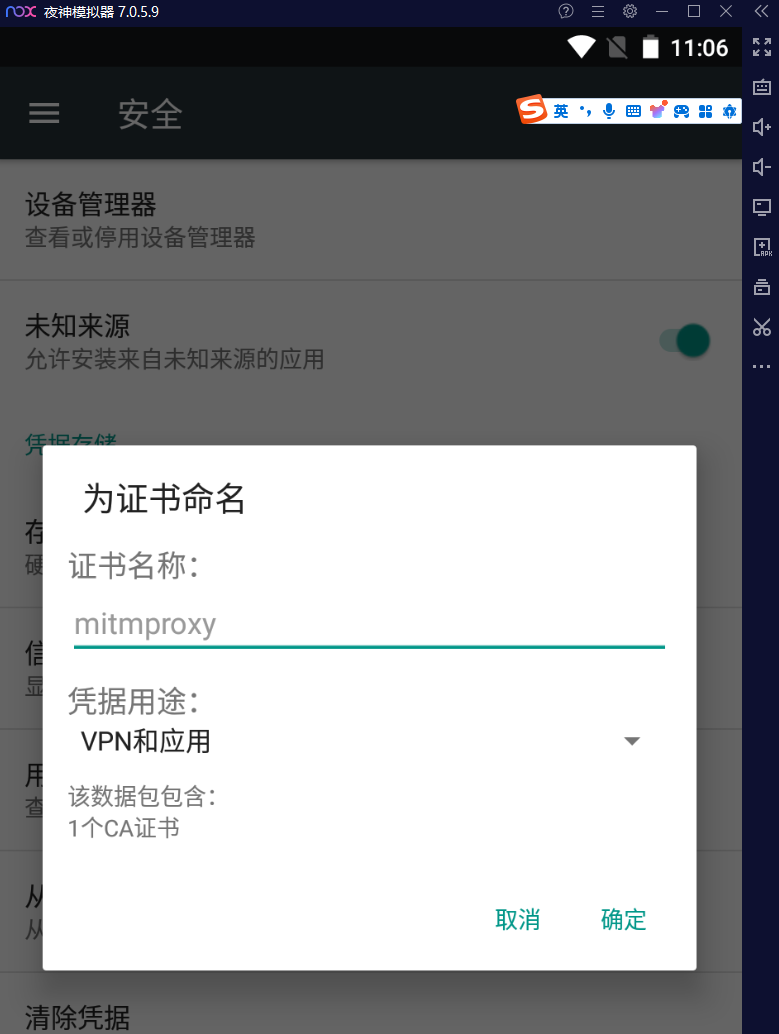
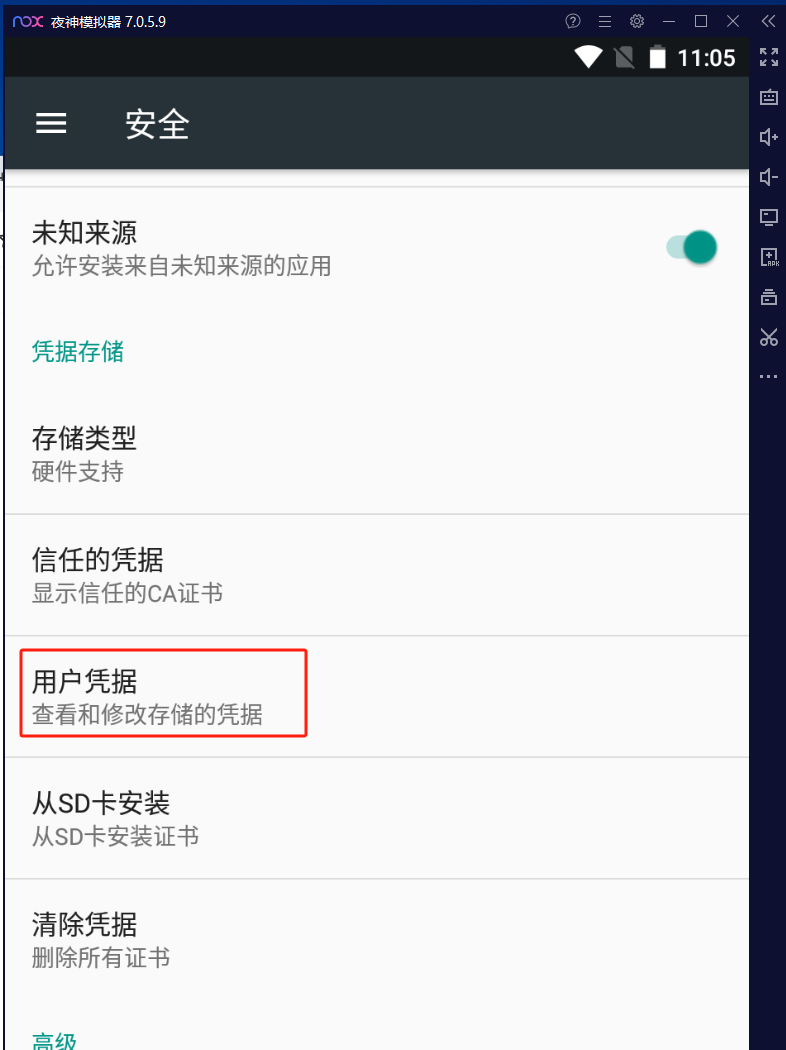
查看证书可以点击“用户凭据”
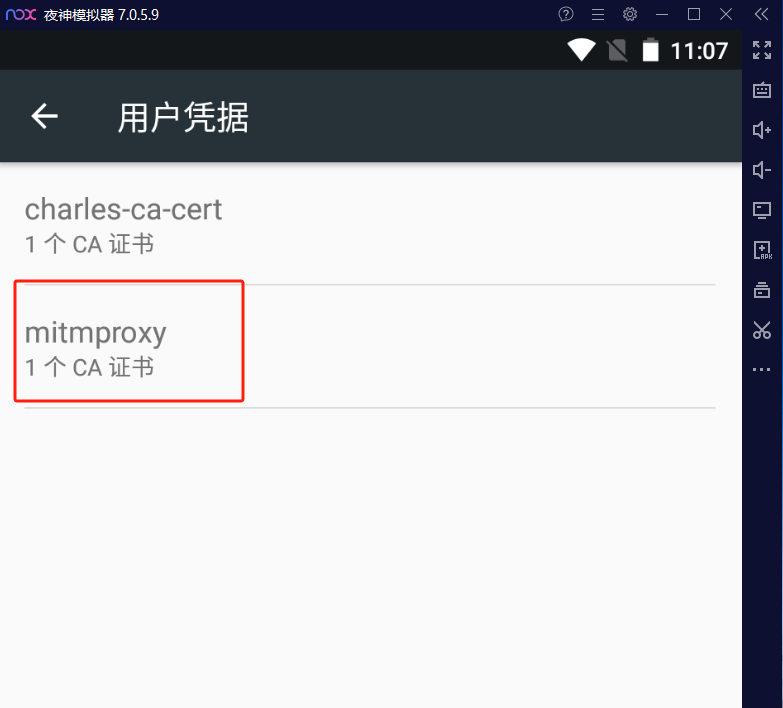
可以看到mitmproxy的CA证书已经安装好了。
2、模拟器安卓操作系统配置代理
安装好了CA证书,还要配置模拟器安卓操作系统的网络代理。
点击模拟其中的无线和网络中的WLAN
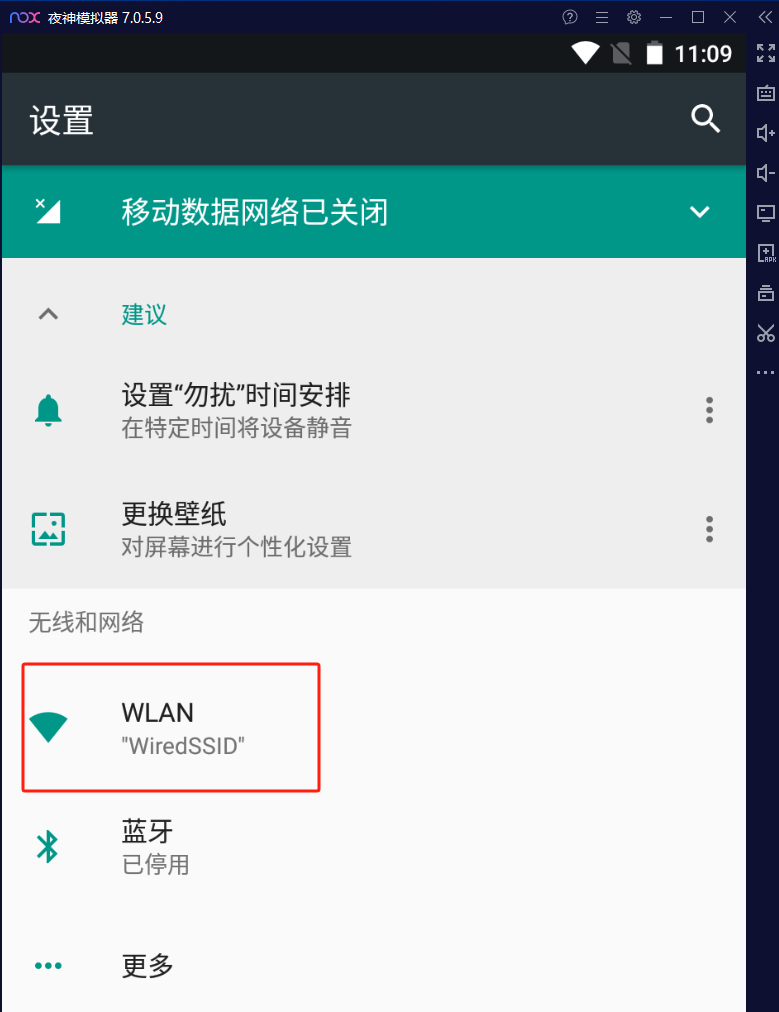
选择默认的无线连接WiredSSID在弹出的菜单中选择“修改网络”
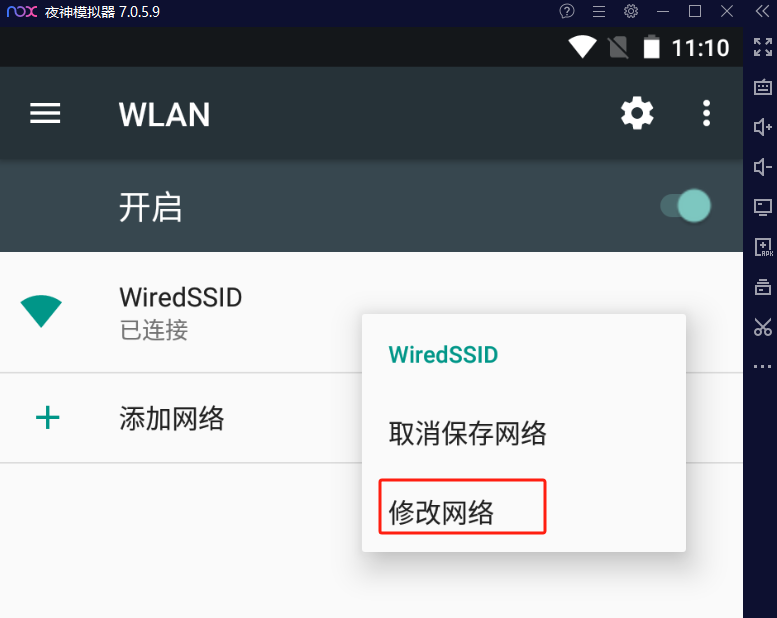
设置mitmproxy的服务器主机IP和代理服务器端口,服务器主机IP就是宿主机windows主机的IP,端口就是起mitmproxy服务的端口。
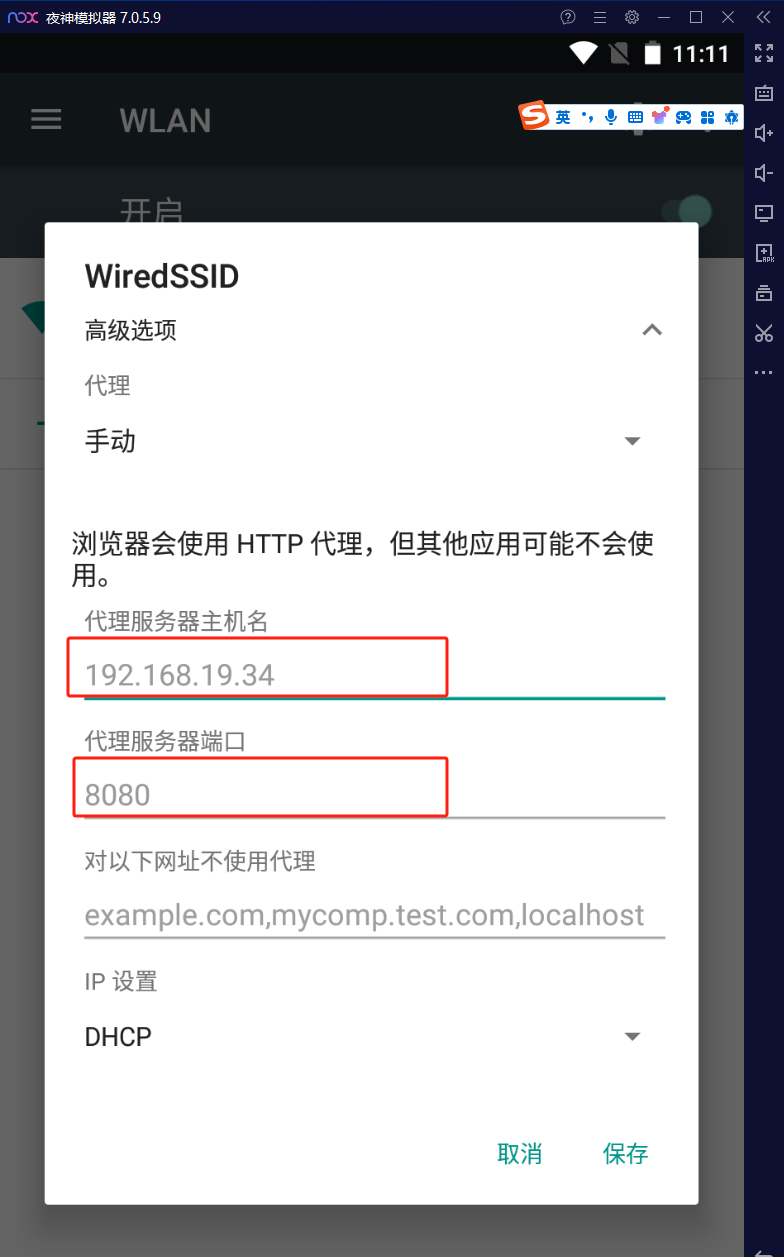
mitmproxy和模拟器都准备好以后就可以分析京东金榜的数据了。
二、分析数据
京东金榜H5小程序的地址是 https://h5.m.jd.com/babelDiy/Zeus/32xRoXWmepbBVHfDMoHMw2kGfHdF/index.html
我们可以用浏览器访问这个地址来分析需要爬取数据的接口和相应返回的数据格式。在这里可以到到京东金榜的数据接口是https://api.m.jd.com/client.action,通过POST请求来获取的金榜数据。
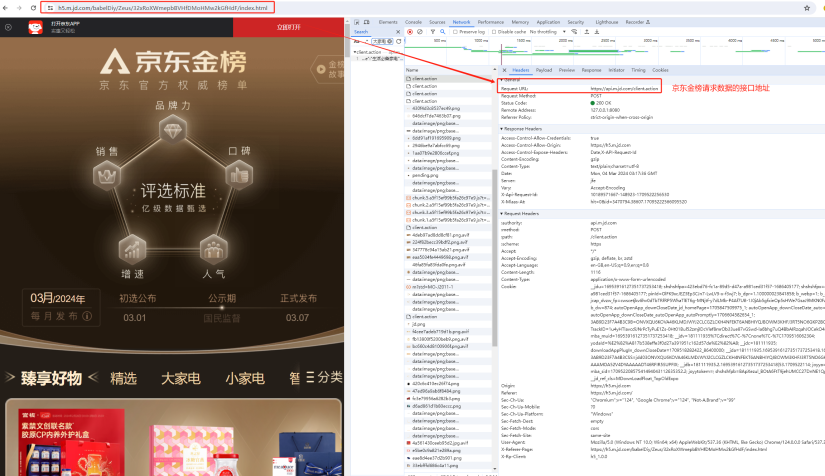
通过Preview仔细分析数据接口返回的金榜数据的JSON格式
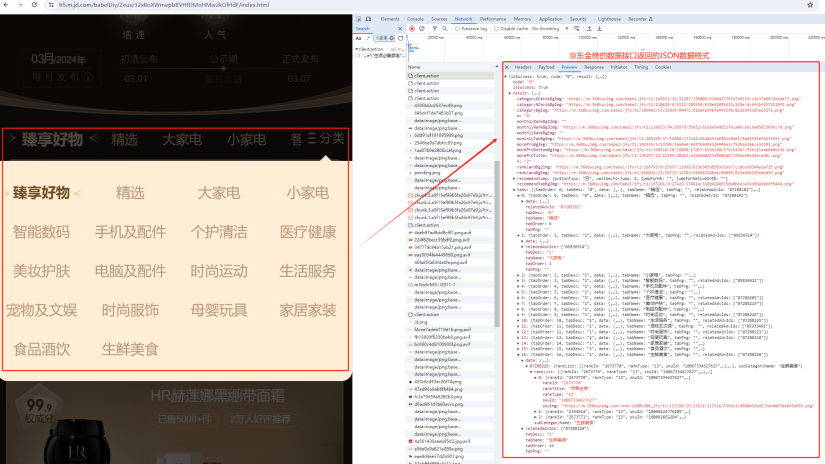
接下来我们就要根据接口和JSON格式的数据来写代码获取并解析相应的数据信息。
三、爬取数据
在这里我们通过response接口获取通过mitmproxy代理后的流量进行解析,实现对京东金榜数据的获取。爬取数据的jdrank_scripts.py具体代码如下:
import json
def response(flow):
url = 'https://api.m.jd.com/client.action'
if flow.request.url.startswith(url):
text = flow.response.text
json_data = json.loads(text)
#print(json_data)
#获取金榜排行
if ('result' in json_data) and ('tabs' in json_data['result']):
getMainGoldRank(json_data)
#获取金榜排行商品列表
if ('result' in json_data) and ('mainRank' in json_data['result']):
getJDProductInfo(json_data)
#获取商品信息
if flow.request.url.startswith(url):
text = flow.response.text
json_data = json.loads(text)
if ('floors' in json_data) and len(json_data['floors'])>1:
prod_skuId=json_data['floors'][0].get('data').get('extMap').get('skuId')
prod_introduceInfo=text
print('-------prod_skuId-------:+++',prod_skuId)
print(prod_skuId, prod_introduceInfo)
# 获取金榜列表
def getMainGoldRank(json_data):
tabs = json_data['result']['tabs']
for tab in tabs:
tabName = tab['tabName'] # 榜单名称
tabData = tab['data'] # 榜单数据
print(type(tabData))
if type(tabData) is list:
for rankdata in tabData:
rankId = rankdata['id']
rankTitle = rankdata['name']
rankType = rankdata['rankType']
skuId=None
print(tabName, rankId, rankType, rankTitle, skuId)
if type(tabData) is dict:
relatedAdvIds = tab['relatedAdvIds']
if type(relatedAdvIds) is list:
for relatedAdvId in relatedAdvIds:
rankList = tabData[relatedAdvId]['rankList']
for rankdata in rankList:
rankId = rankdata['rankId']
rankTitle = rankdata['rankType']
rankType = rankdata['rankTitle']
skuId = rankdata['skuId']
print(tabName, rankId, rankType, rankTitle, skuId)
#获取JD金榜商品概要信息
def getJDProductInfo(json_data):
#if ('result' in json_data) and ('mainRank' in json_data['result']):
print(json_data)
try:
products=json_data['result']['mainRank']['products']
prod_main_rank=json_data['result']['mainRank']
prod_rankId=prod_main_rank.get('id')
#判断如果没有在main_gold_rank表中则添加记录至main_gold_rank表
rankTitle=prod_main_rank.get('name')
print('', prod_rankId,rankTitle , 13, '')
for product in products:
prod_skuId = product['product']['skuId']
prod_name = product['product']['name']
prod_img = product['product']['img']
prod_skuSallingPoint = product.get('skuSallingPoint')
prod_saleInfoStr = product.get('saleInfoStr')
prod_simpleSaleInfoStr = product.get('simpleSaleInfoStr')
prod_totalBuyInfoStr = product.get('totalBuyInfoStr')
prod_goodCountStr = product.get('goodCountStr')
prod_simpleGoodCountStr = product.get('simpleGoodCountStr')
prod_totalPopularity = product.get('totalPopularity')
prod_popularityStr = product.get('popularityStr')
prod_cmttTag = product.get('cmttTag')
prod_longTitle = product.get('longTitle')
prod_authorityScore = product.get('authorityScore')
prod_saleScore = product.get('saleScore')
prod_popularityScore = product.get('popularityScore')
prod_growthScore = product.get('growthScore')
prod_praiseScore = product.get('praiseScore')
prod_brandScore = product.get('brandScore')
prod_brandStr = product.get('brandStr')
prod_growthStr = product.get('growthStr')
prod_sortedSaleIfoStr = product.get('sortedSaleIfoStr')
prod_rankNum = product.get('rankNum')
print(prod_rankId,prod_skuId,prod_name,prod_img,prod_skuSallingPoint,prod_saleInfoStr,prod_simpleSaleInfoStr,prod_totalBuyInfoStr,
prod_goodCountStr,prod_simpleGoodCountStr,prod_totalPopularity,prod_popularityStr,prod_cmttTag,prod_longTitle,
prod_authorityScore,prod_saleScore,prod_popularityScore,prod_growthScore,prod_praiseScore,prod_brandScore,prod_brandStr,prod_growthStr,prod_sortedSaleIfoStr,prod_rankNum)
except Exception as e:
print('getJDProductInfo Error:', e)
通过运行 mitmdump -s jdrank_scripts.py
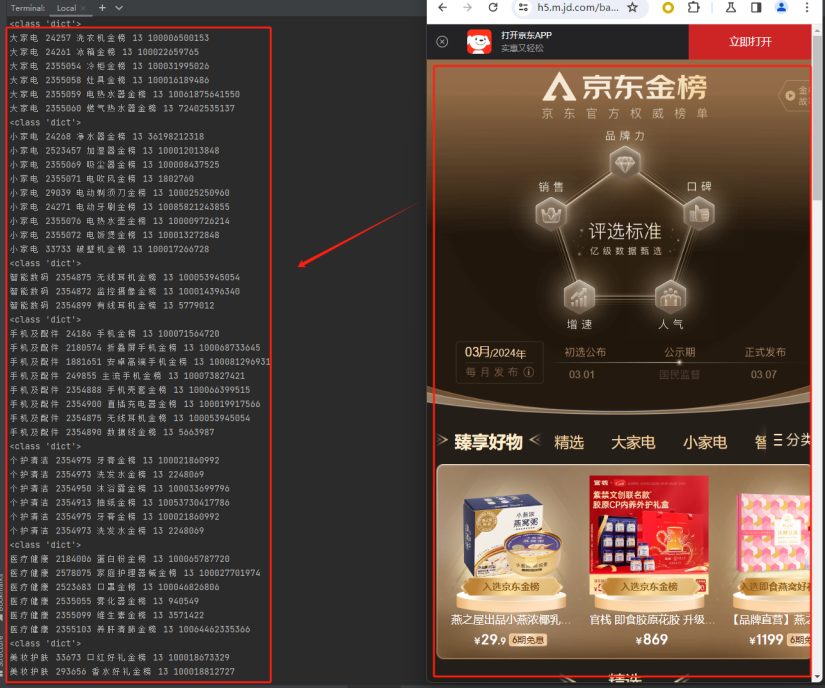
用浏览器访问京东H5的小程序https://h5.m.jd.com/babelDiy/Zeus/32xRoXWmepbBVHfDMoHMw2kGfHdF/index.html
从H5的小程序访问获取京东金榜的排行数据
获取京东金榜商品信息
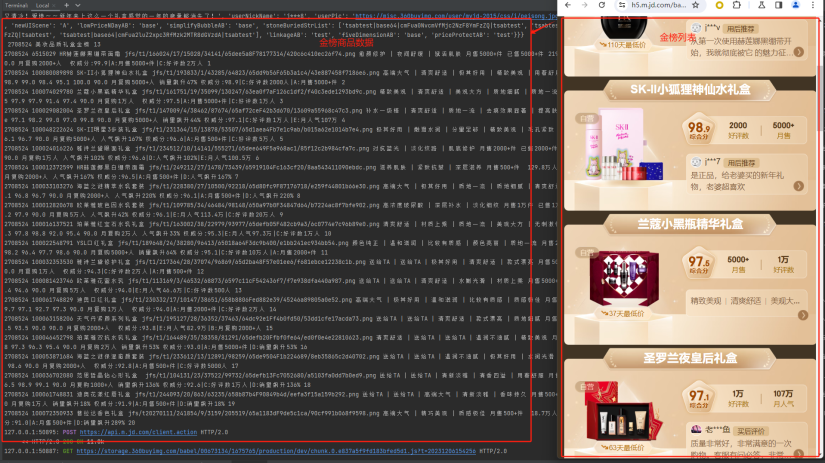
从京东APP上访问京东金榜也是同样的效果。
至此,本文从环境准备到数据分析到代码实现,通过mitmdump爬取京东金榜排行数据进行mitmproxy爬取数据的实战。
作者博客:http://xiejava.ishareread.com/

关注:微信公众号,一起学习成长!