

前期出了一个《爬取京东商品评价信息实战》的教程,最近又有网友提到要出一个爬淘宝商品评论的教程。说实话淘宝的反爬机制做得比京东要严,所以用爬取京东商品评价信息的方式取爬取淘宝商品评价不太可行。本文还是介绍通过Selenium模拟登录后来进行淘宝商品评价信息的爬取。 Selenium安装与配置及如何模拟登录淘宝见《Selenium安装与配置》及《Selenium实战-模拟登录淘宝并爬取商品信息》
一、分析需要爬取的页面
淘宝的商品评价信息在商品详情页面,需要登录淘宝后,访问到商品详情页,并且需要点击“宝贝评价”才能看到相应的商品评价信息。
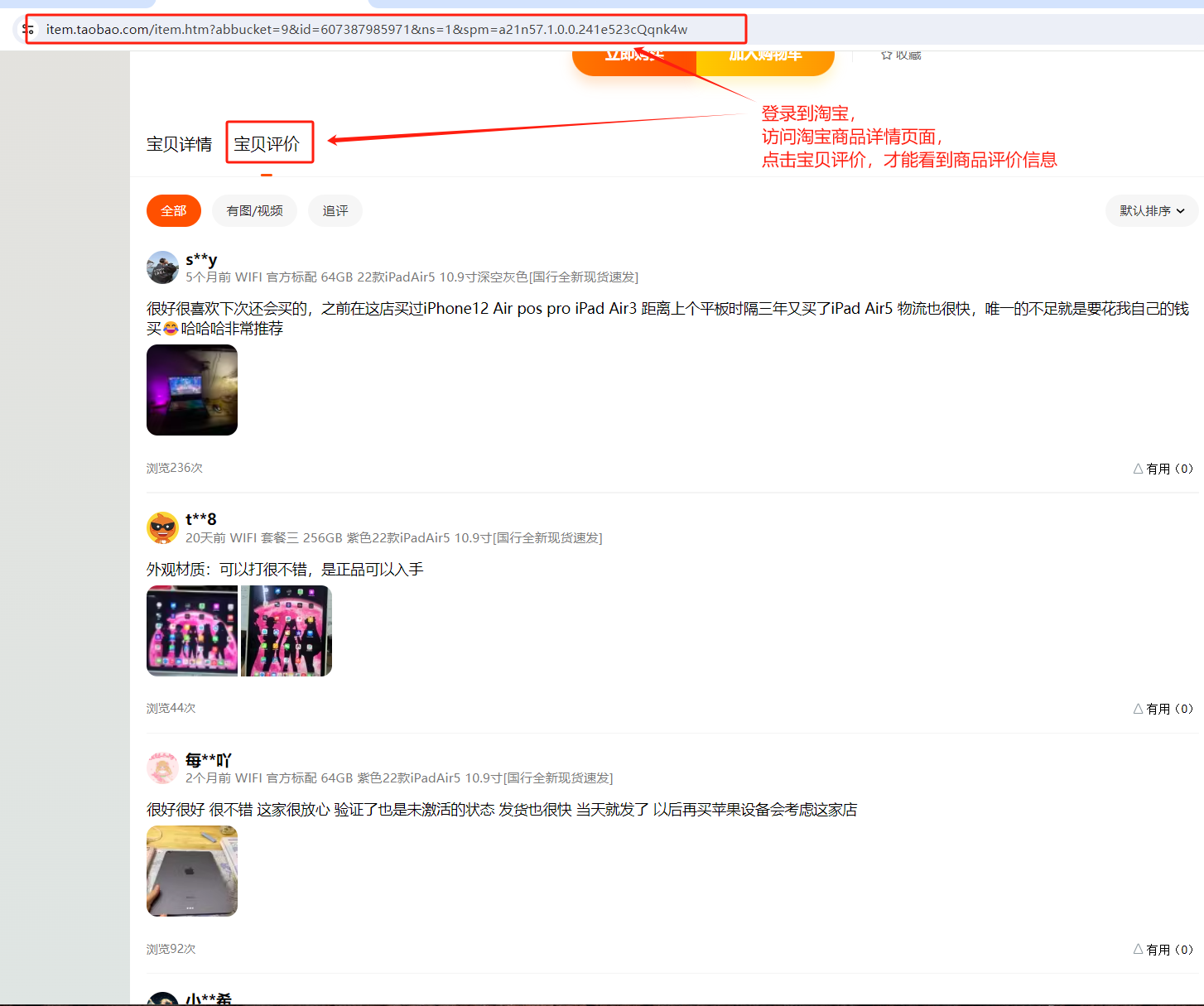
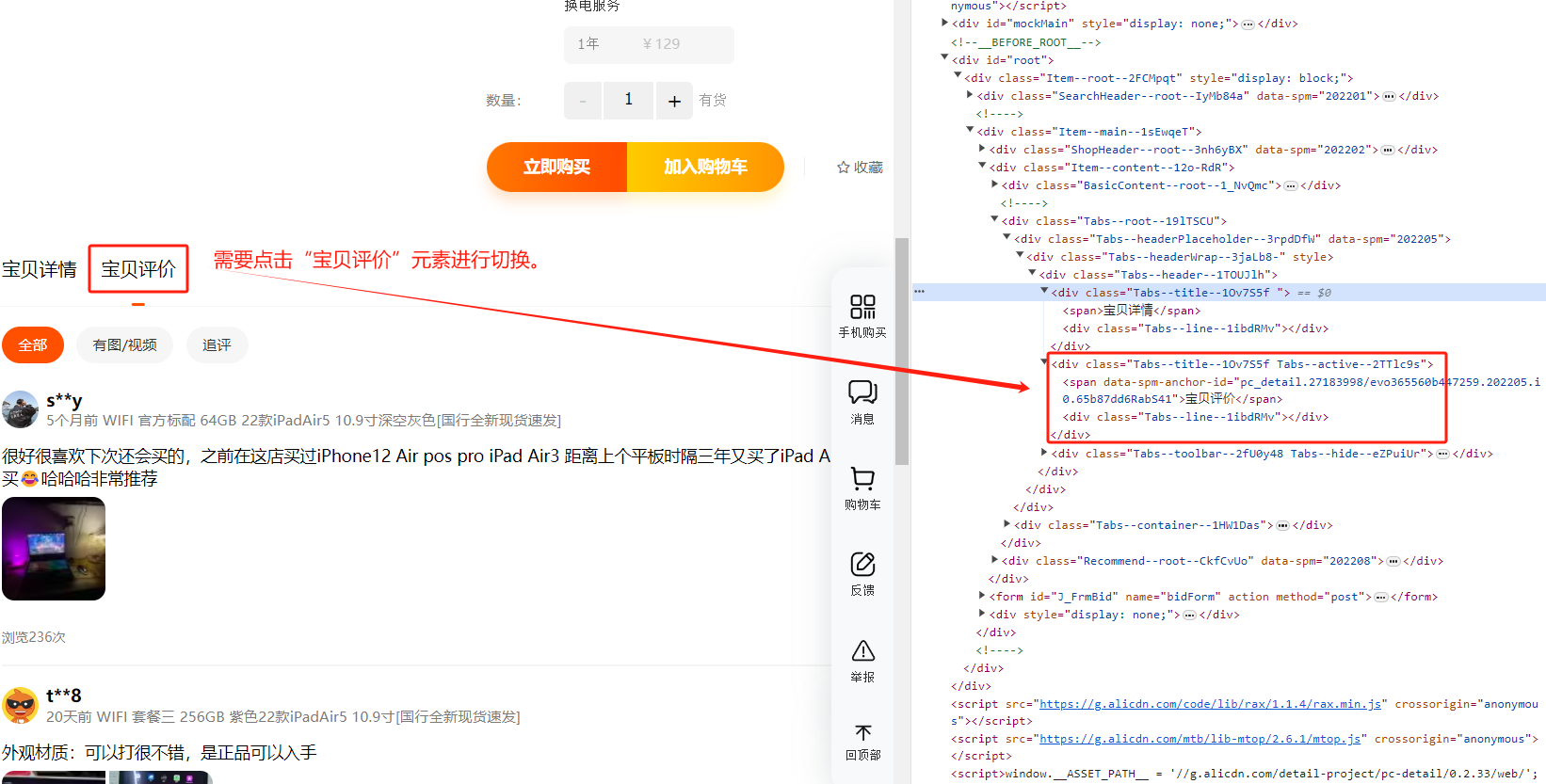
我们还是要通过chrome浏览器的调试模式来分析需要点击哪个页面元素才能看到具体的评价信息。通过分析可以得知要点击<div class="Tabs--title--1Ov7S5f Tabs--active--2TTlc9s"><span data-spm-anchor-id="pc_detail.27183998/evo365560b447259.202205.i0.65b87dd6RabS41">宝贝评价</span><div class="Tabs--line--1ibdRMv"></div></div> 这个元素才能进行切换到宝贝评价。
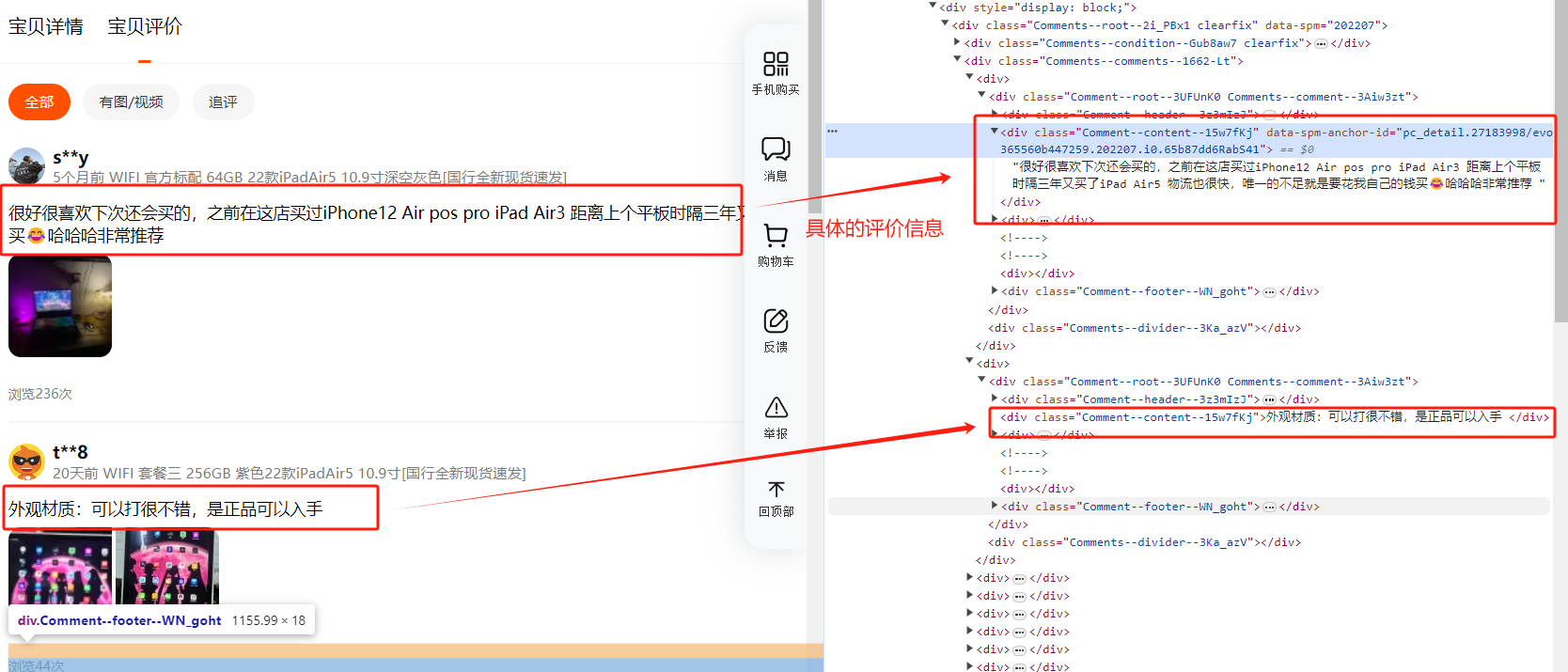
具体的评价信息是在<div class="Comment--content--15w7fKj" data-spm-anchor-id="pc_detail.27183998/evo365560b447259.202207.i0.65b87dd6RabS41">很好很喜欢下次还会买的,之前在这店买过iPhone12 Air pos pro iPad Air3 距离上个平板时隔三年又买了iPad Air5 物流也很快,唯一的不足就是要花我自己的钱买😂哈哈哈非常推荐 </div> 这些<div class="Comment--content--15w7fKj">......</div>元素里。
分析完页面后,就可以开始思考如何编码了。
二、实现爬取商品评价信息的代码
通过上面的分析,我们要获取商品评价信息,需要让Selenium进行模拟登录->访问商品列表页面->访问商品详情页面->点击“宝贝评价”->获取并解析商品评价信息。 前面让Selenium进行模拟登录->访问商品列表页面在《Selenium实战-模拟登录淘宝并爬取商品信息》已有介绍。这里主要介绍后面的部分,访问商品详情页面->点击“宝贝评价”->获取并解析商品评价信息。 获取并解析商品评价信息有两种方式,一种是通过解析显示评价信息的元素获取,一种是通过mitmproxy代理进行流量抓包获取。
1、通过解析显示评价信息的元素获取商品评价信息
selenium_taobao.py的部分代码参考如下:
# 解析获取商品信息
def get_products():
"""提取商品数据"""
html = driver.page_source
doc = pq(html)
items = doc('.Card--doubleCardWrapper--L2XFE73').items()
for item in items:
product = {'url': item.attr('href'),
'price': item.find('.Price--priceInt--ZlsSi_M').text(),
'realsales': item.find('.Price--realSales--FhTZc7U-cnt').text(),
'title': item.find('.Title--title--jCOPvpf').text(),
'shop': item.find('.ShopInfo--TextAndPic--yH0AZfx').text(),
'location': item.find('.Price--procity--_7Vt3mX').text()}
print(product)
item_href=item.attr('href') # 得到商品的详情访问页面
if item_href.find('https:')>=0:
item_url =item_href
print(item_url)
else:
item_url = "https:" + item.attr('href')
# 爬取商品评价
get_prod_comments(item_url)
time.sleep(sleeptime)
# 爬取商品评价
def get_prod_comments(item_url):
driver.get(item_url)
print('跳转至详情页.......'+item_url)
ele = wait.until(EC.element_to_be_clickable((By.XPATH, "//div[@class='Tabs--title--1Ov7S5f ']/span")))
time.sleep(sleeptime)
# 向下滚动至目标元素可见
js = "arguments[0].scrollIntoView();"
driver.execute_script(js, ele)
print('向下滚动至-宝贝评价-元素可见.......')
driver.execute_script("arguments[0].click();", ele)
print('点击-宝贝评价.......')
ele_comments=driver.find_elements(By.CSS_SELECTOR,".Comment--content--15w7fKj")
print('提取宝贝评价信息.......')
for ele_comment in ele_comments:
print(ele_comment.text)
在解析获取商品信息的方法中通过item_href=item.attr('href') # 得到商品的详情访问页面
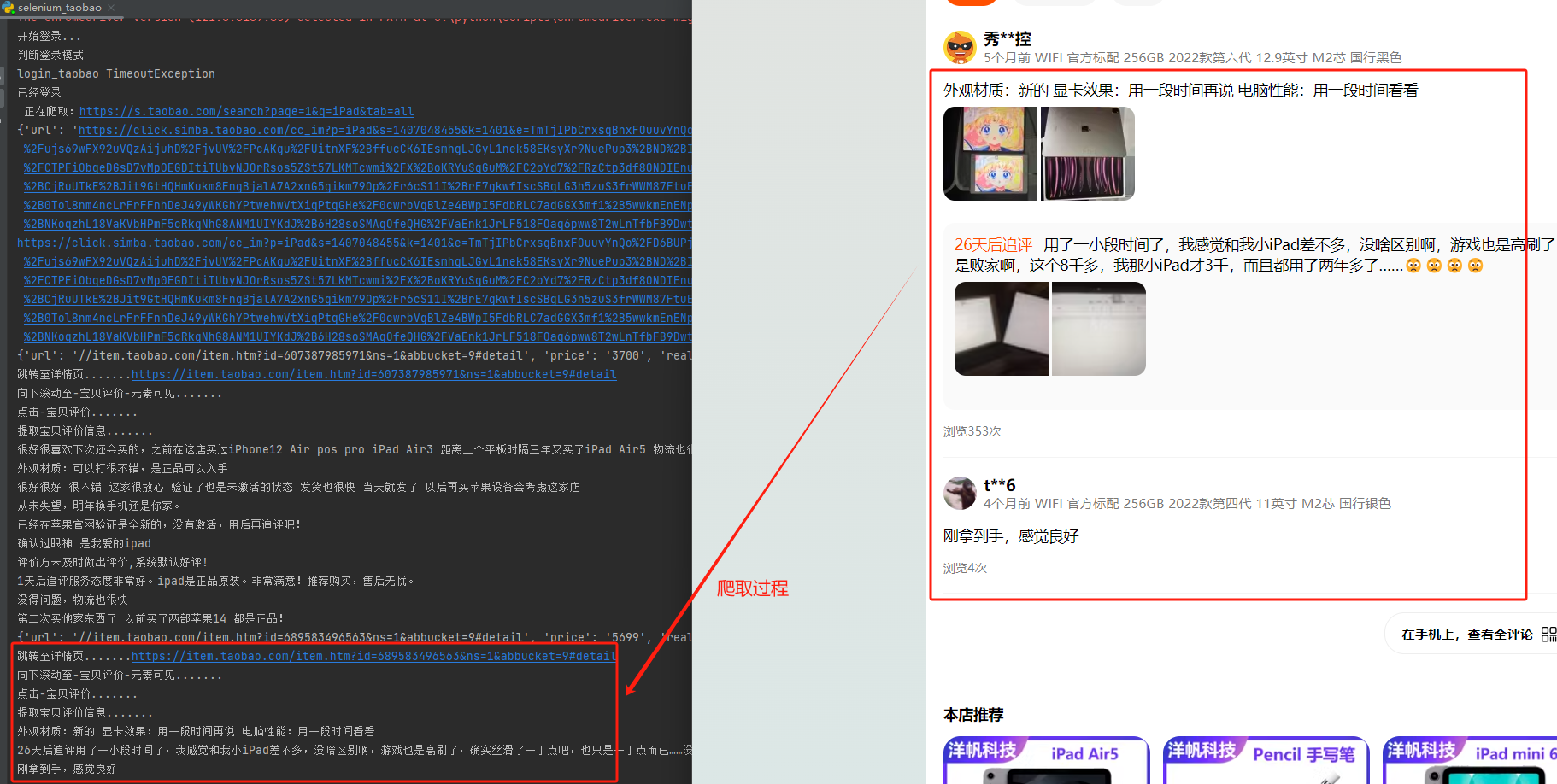
在爬取商品评价get_prod_comments(item_url)的方法中,通过driver.get(item_url)跳转到了商品详情页面。通过ele = wait.until(EC.element_to_be_clickable((By.XPATH, "//div[@class='Tabs--title--1Ov7S5f ']/span")))定位到“宝贝评价”的点击按钮,通过driver.execute_script("arguments[0].click();", ele)进行点击事件,然后通过ele_comments=driver.find_elements(By.CSS_SELECTOR,".Comment--content--15w7fKj")找到显示评价信息的元素,循环后解析具体的评价文本信息。
效果如下:
2、通过mitmproxy代理进行流量抓包获取商品评价信息
既然通过Selenium进行模拟点击“宝贝评价”访问了商品评价信息,也可通过流量抓包的方式来获取商品评价信息。
同样chrome浏览器的调试模式来分析商品评价是从哪些接口返回的数据,这里可以看到宝贝评价是通过https://h5api.m.taobao.com/h5/mtop.alibaba.review.list.for.new.pc.detail/1.0/....接口返回的数据。
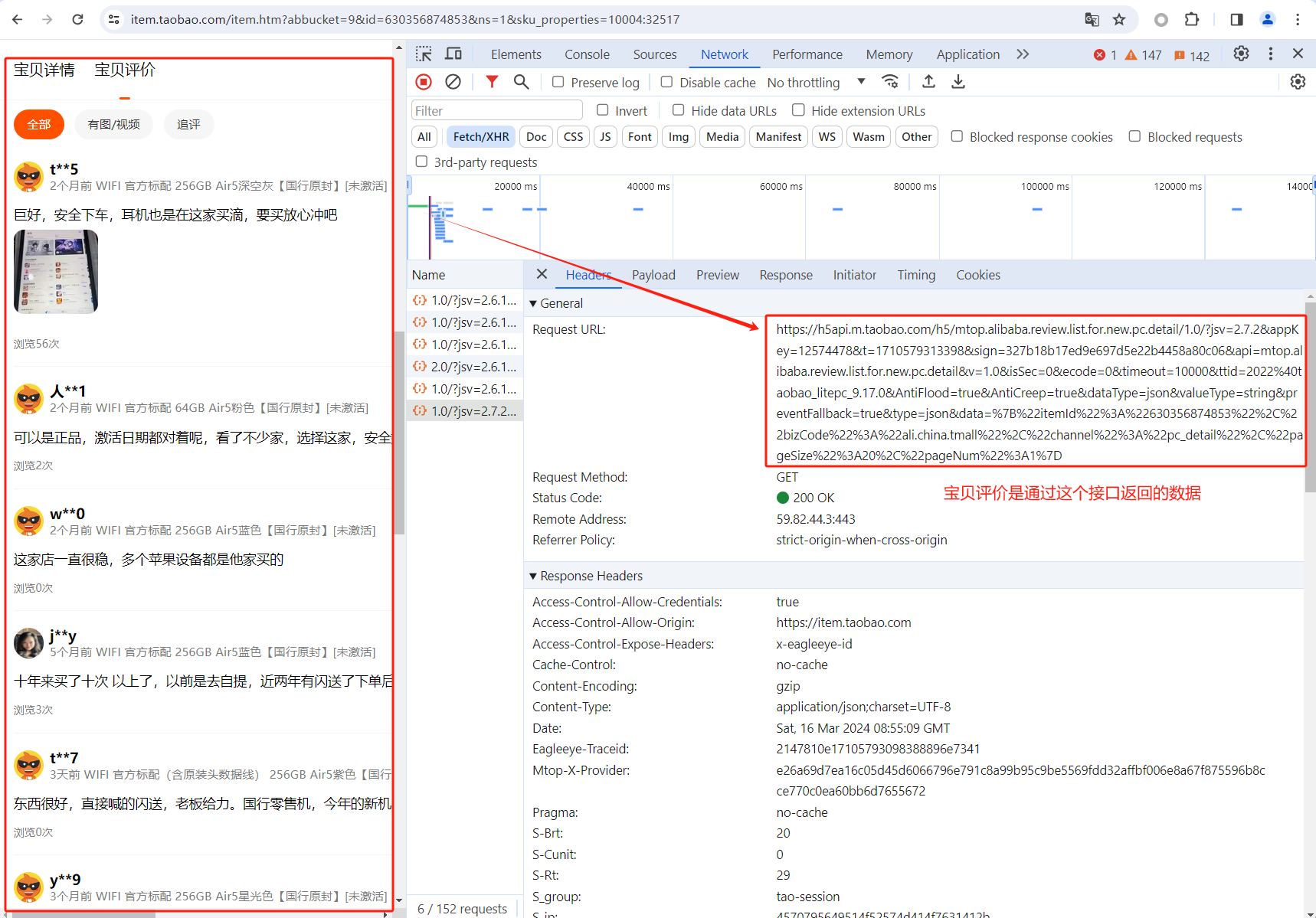
切换到Response,可以看到接口返回的宝贝评价JSON串。
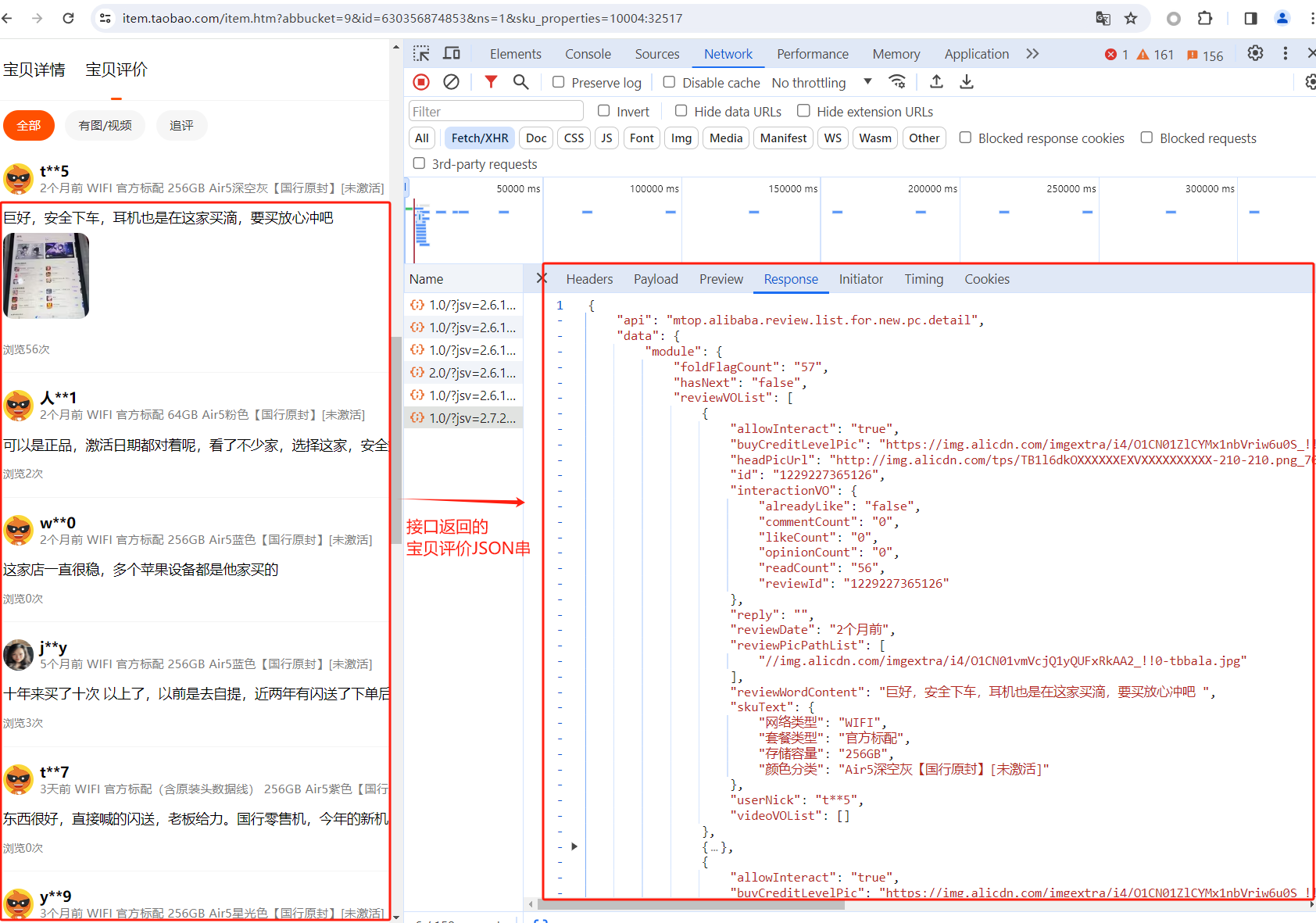
有了这些信息后,就可以写mitmproxy代理抓包的代码了。 taobao_scripts.py代码如下:
import json
# 抓取淘宝商品评价信息
def response(flow):
url = 'https://h5api.m.taobao.com/h5/mtop.alibaba.review.list.for.new.pc.detail'
if flow.request.url.startswith(url):
text = flow.response.text
json_data = json.loads(text)
print(json_data)
在控制台运行 mitmdump -s taobao_scripts.py 启动mitmproxy代理服务。具体参考《Selenium实战-模拟登录淘宝并爬取商品信息》设置好chrome浏览器的mitmproxy代理。然后运行selenium_taobao.py通过Selenium驱动浏览器,进行自动模拟登录->访问商品列表页面->访问商品详情页面->点击“宝贝评价”。
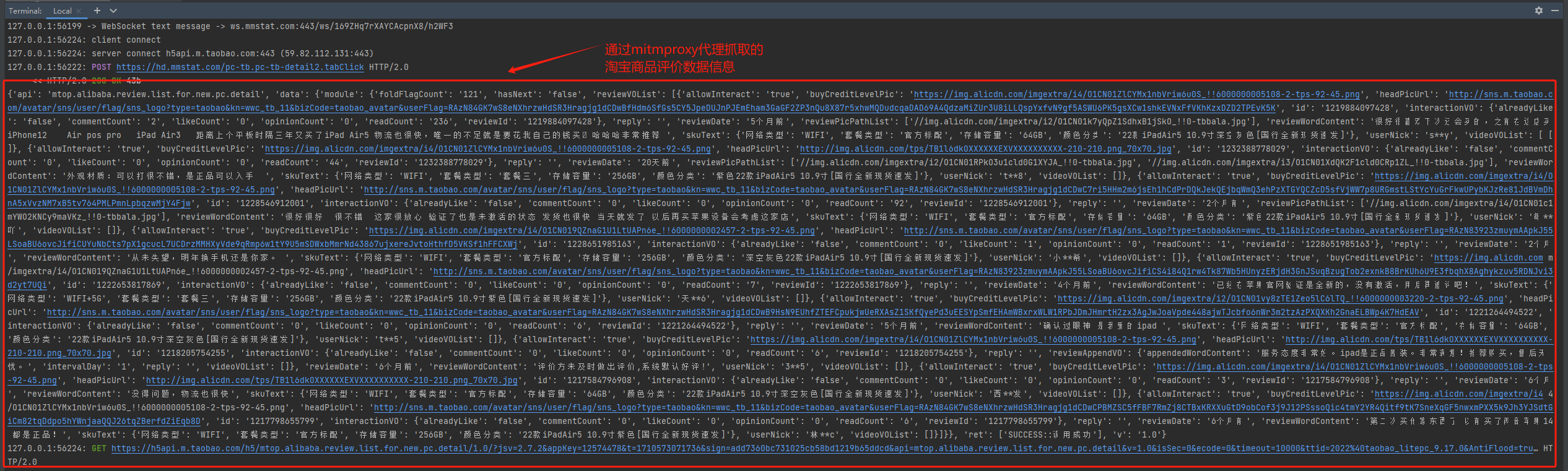
在运行mitmdump的控制台可以看到通过抓包获取的淘宝商品评价的数据信息。
效果如下图:
三、附-完整代码
selenium_taobao.py完整代码如下
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.common import TimeoutException, NoSuchElementException
from urllib.parse import quote
from pyquery import PyQuery as pq
import time
sleeptime=5
chrome_options = Options()
chrome_options.add_experimental_option("debuggerAddress", "localhost:9222") #此处端口保持和命令行启动的端口一致
driver = Chrome(options=chrome_options)
driver.implicitly_wait(5) # 隐式等待
wait = WebDriverWait(driver, 10) # 显示等待
# 模拟淘宝登录
def login_taobao():
print('开始登录...')
try:
login_url='https://login.taobao.com/member/login.jhtml'
driver.get(login_url)
check_login_type()
input_login_id = wait.until(EC.presence_of_element_located((By.ID, 'fm-login-id')))
input_login_password = wait.until(EC.presence_of_element_located((By.ID, 'fm-login-password')))
input_login_id.send_keys('your account')
input_login_password.send_keys('your password')
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.fm-button.fm-submit.password-login')))
submit.click()
is_loging = wait.until(EC.url_changes(login_url))
return is_loging
except TimeoutException:
print('login_taobao TimeoutException')
submit = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR, '.fm-button.fm-submit')))
submit.click()
is_loging = wait.until(EC.url_changes(login_url))
if is_loging:
return is_loging
else:
login_taobao()
# 判断登录模式,如果是扫描登录则切换到用户名密码登录模式
def check_login_type():
print('判断登录模式')
try:
wait.until(EC.presence_of_element_located((By.ID, 'fm-login-id')))
except TimeoutException:
change_type = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '.iconfont.icon-password')))
change_type.click() # 切换到用户密码模式登录
print('切换到用户密码模式登录...')
# 解析获取商品信息
def get_products():
"""提取商品数据"""
html = driver.page_source
doc = pq(html)
items = doc('.Card--doubleCardWrapper--L2XFE73').items()
for item in items:
product = {'url': item.attr('href'),
'price': item.find('.Price--priceInt--ZlsSi_M').text(),
'realsales': item.find('.Price--realSales--FhTZc7U-cnt').text(),
'title': item.find('.Title--title--jCOPvpf').text(),
'shop': item.find('.ShopInfo--TextAndPic--yH0AZfx').text(),
'location': item.find('.Price--procity--_7Vt3mX').text()}
print(product)
item_href=item.attr('href') # 得到商品的详情访问页面
if item_href.find('https:')>=0:
item_url =item_href
print(item_url)
else:
item_url = "https:" + item.attr('href')
# 爬取商品评价
get_prod_comments(item_url)
time.sleep(sleeptime)
# 爬取商品评价
def get_prod_comments(item_url):
driver.get(item_url)
print('跳转至详情页.......'+item_url)
ele = wait.until(EC.element_to_be_clickable((By.XPATH, "//div[@class='Tabs--title--1Ov7S5f ']/span")))
time.sleep(sleeptime)
# 向下滚动至目标元素可见
js = "arguments[0].scrollIntoView();"
driver.execute_script(js, ele)
print('向下滚动至-宝贝评价-元素可见.......')
driver.execute_script("arguments[0].click();", ele)
print('点击-宝贝评价.......')
ele_comments=driver.find_elements(By.CSS_SELECTOR,".Comment--content--15w7fKj")
print('提取宝贝评价信息.......')
for ele_comment in ele_comments:
print(ele_comment.text)
# 自动获取商品信息并自动翻页
def index_page(url,cur_page,max_page):
print(' 正在爬取:'+url)
try:
driver.get(url)
get_products()
next_page_btn = wait.until(EC.element_to_be_clickable((By.XPATH, '//button/span[contains(text(),"下一页")]')))
next_page_btn.click()
do_change = wait.until(EC.url_changes(url))
if do_change and cur_page<max_page:
new_url=driver.current_url
cur_page = cur_page + 1
index_page(new_url,cur_page,max_page)
except TimeoutException:
print('---index_page TimeoutException---')
if __name__ == '__main__':
is_loging=login_taobao()
if is_loging:
print('已经登录')
KEYWORD = 'iPad'
url = 'https://s.taobao.com/search?page=1&q=' + quote(KEYWORD) + '&tab=all'
max_page=1
index_page(url,1,max_page)
作者博客:http://xiejava.ishareread.com/

关注:微信公众号,一起学习成长!