在数据分析的过程中,分析师常常希望通过多个维度多种方式来观察分析数据,重塑和透视是常用的手段。 数据的重塑简单说就是对原数据进行变形,为什么需要变形,因为当前数据的展示形式不是我们期望的维度,也可以说索引不符合我们的需求。对数据的重塑不是仅改变形状那么简单,在变形过程中,数据的内在数据意义不能变化,但数据的提示逻辑则发生了重大的改变。 数据透视是最常用的数据汇总工具,Excel 中经常会做数据透
在数据分析的过程中,分析师常常希望通过多个维度多种方式来观察分析数据,重塑和透视是常用的手段。 数据的重塑简单说就是对原数据进行变形,为什么需要变形,因为当前数据的展示形式不是我们期望的维度,也可以说索引不符合我们的需求。对数据的重塑不是仅改变形状那么简单,在变形过程中,数据的内在数据意义不能变化,但数据的提示逻辑则发生了重大的改变。 数据透视是最常用的数据汇总工具,Excel 中经常会做数据透
在数据分析过程中,经常会需要根据某一列或多列把数据划分为不同的组别,然后再对其进行数据分析。本文将介绍pandas的数据分组及分组后的应用如对数据进行聚合、转换和过滤。 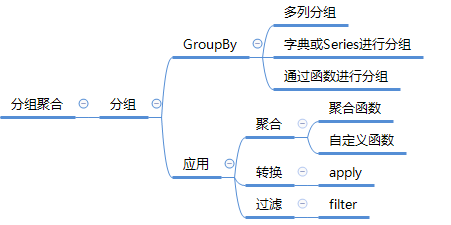 在关系型数据库中我们常用SQL的GROUP BY操作进
在许多应用中,数据可能来自不同的渠道,在数据处理的过程中常常需要将这些数据集进行组合合并拼接,形成更加丰富的数据集。pandas提供了多种方法完全可以满足数据处理的常用需求。具体来说包括有join、merge、concat、append等。 、重复值、异常值的处理。对于数据清洗一般也是分两个步骤,第一步就
对数据集进行排序和排名的是常用最基础的数据分析手段,pandas提供了方便的排序和排名的方法,通过简单的语句和参数就可以实现常用的排序和排名。 本文以student数据集的DataFrame为例来演示和介绍pandas数据分析之排序和排名(sort和rank)。 数据集内容如下,包括学生的学号、姓名、年龄及语文、数学、英语的成绩: ```python import pandas as pd i
# 简介 无可非议,pandas是Python最强大的数据分析和探索工具之一,因金融数据分析工具而开发,支持类似于SQL语句的模型,可以对数据进行增删改查等操作,支持时间序列分析,也能够灵活的处理缺失的数据。它含有使数据分析工作变得更快更简单的高级数据结构和操作工具。pandas是基于NumPy构建的,让以NumPy为中心的应用变得更加简单。 这里所说的让pandas变得更快更简单的高级数据结
 pandas 是基于NumPy 的一种工具,该工具是为解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。Pandas的名称来自于面板数据(panel data